TIS3.6.0整合Chunjun介绍
整合Chunjun完善TIS生态
经过几个月时间研发TIS v3.6.0-alpha版本终于发布了。该版本整合了大数据领域数据同步工具的翘楚Chunjun,将TIS的业务能力提升到了新高度。
在v3.6.0-alpha之前TIS已经整合了Alibaba DataX和 Flink-CDC。离线批量同步利用DataX组件实现,而在实时数据同步方面,实时数据变更Source组件
TIS是基于Flink-CDC来实现的,至于Sink部分一直是基于各种数据端提供的生态API包经过二次开发完成的,存在的问题是,开发周期长,调试困难,例如,仅仅为了实现
StarRocks一个Sink端实现了一个基于StreamFunction的Sink实现,连开发带测试化花去了整整三个星期的时间。
直到2022年3月从社区分享中了解到了一个开源架构FlinkX(最近已改名成Chunjun),查阅文档之后发现Chunjun已经很好地支持了大数据领域大部分数据端包括Source和Sink, ,它的Source端基于Polling轮询机制来实现,相较与Flink CDC实现的Source端是有自己的特色的,例如,并不是所有的端都支持类似MySQL binlog这样的实时同步机制 ,即使支持类似Oracle的LogMiner,如需开启,也需要专业Oracle DBA协助,不然设置权限就会吓退很多用户。而基于Polling机制的实时更新订阅却可以支持所有的Source端(只要实现了JDBC接口就行) ,所以Chunjun的Source端通用性非常好,唯独比Flink CDC的劣势是实时性要低,不过一般在大部份OLAP的场景下用户对实时性的要求并没有那么高,所以一般情况下推荐使用Chunjun的Source来监听实时数据变更。
另外,Chunjun的Sink端实现也是一大特色,一般情况下数据端的生态产品中会提供Flink Sink的实现,例如:ElasticSearch的Flink的官网提供了一个基于SinkFunction的实现,StarRocks在官网也提供了Sink实现
但是各家实现方式各不相同,没有一个统一的抽象模型,另外各厂商提供的实现中基本上只是一些半成品,像容灾、监控等都没有提供,导致TIS在整合各家Sink端时着实花了不少精力且很难做得完美。
因此在TISv3.6.0中利用Chunjun v1.12.5全面改写了TIS原有的Sink端实现,由于Chunjun实现是一个封装好并且已经在生产环境中经过检验的,
并且在实现方式上已经通过统一建模,每种端的接入方式可以统一,对TIS来说大大提高了整合开发效率,而且将容灾、监控、脏数据管理也一并实现。
由于Chunjun支持的Connector端非常丰富,TISv3.6.0中只是拣取了几个用户高频使用的端来封装,其他端的封装会在后续版本中逐步实现。以下是v3.6.0版本中实现的端
| 端类型 | Source | Sink |
|---|---|---|
| ClickHouse | yes | |
| Doris | yes | |
| PostgreSQL | yes | yes |
| Oracle | yes | yes |
| MySQL | yes | yes |
TIS来者何人?
TIS经过四年发展,最早基于Solr,为用户提供一站式式开箱即用、自助服务的搜索引擎中台产品。 在2020年之前当Flink和MPP引擎还没有形成气候之时 ,TIS就已经在为互联网企业内部提供实时OLAP分析需求的服务。搜索引擎开源框架Lucene和基于之上构建起来的Solr引擎,其实是一个非常强大的实时数据引擎,几乎可以处理当下的大数据领域大部分的OLAP分析需求。
现在ClickHouse中主打的非常强大的列式存储,以及,Doris和StarRock的FE/BE的分布式架构,Lucene和Solr中早在2015年的时候就已经发展得非常成熟。
但是Lucene/Solr有一个致命的短板是,它对客户端不太友好,对引擎的访问没有使用SQL的方式来操作的,针对用户特定的OLAP的查询需求,需要在引擎端开发定制插件才能实现。
这就大大阻碍了利用搜索引擎来解决业务系统中OLAP需求的推广,其实Lucene/Solr社区也意识到了这个问题,作了一些针对SOL的支持工作,但为时已晚。
2020年之后基于MPP架构的产品如雨后春笋地发展起来,例如,Clickhouse,Doris,StarRocks,kylin,DataX,SeaTunnel等,加之流式计算框架Flink逐渐走向成熟,通过开源工具栈组合的方式来构建企业内部实时数仓 的技术门槛不再那么遥不可及。
市面上有如此丰富工具栈,且各有特色,企业大数据架构师需要结合自身业务特点来进行解决方案选型。能够快速将工具栈进行整合,并且让每个工具栈之间进行无缝对接,满足大数据业务需求, 成为当下大数据领域的技术痛点。
因此,TIS从2019年底开始转型,开始全方位支持现有实时数仓中台,从原先与搜索引擎强耦合的技术架构进行重构。实时数仓的几个流程ETL(采集、处理、加载)流程缺一不可,这个和搜索引擎构建的流程是一致的, 所以搜索引擎中台中大部分组件代码是可以复用的,但,从只处理搜索引擎一个场景,要兼容到所有数据端的大数据生态场景,问题的复杂度发生了质的变化,其中有不小的挑战。 能够控制复杂度,成为决定TIS是否能够成功的关键。从用户的视角出发,用户需要一个开箱即用的一站式工具套件,最好点几下鼠标就不需求给实现了。 从TIS的开发者角度来看需要一个可以对每个数据端进行分而治之,每个功能点的引入不能既有功能有丝毫影响。
最终,TIS呈现在用户面前的应该是这样一个产品,用户进入TIS系统,就像来到一个自助餐厅,各种组件都放在一个可视化仓库中,用户根据自己口味,将仓库中的组件放到自己的托盘中,
TIS内部有一套强大的元数据管理系统,根据用户需求大部分的工作脚本可自动生成(TIS是基于模型的DataOps区别与市面上其他基于脚本任务的DevOps系统,具体来说,很多系统是帮用户构建一个执行流程
,而流程中所要执行的任务是提供了一个TextArea的输入框,让用户自己填写json、yaml、xml之类的配置文件,而TIS完全摒弃了这一方法),等到任务所需资源准备好,用户轻点数据系统就开始运行。
另外更为关键的标志是,TIS是能够将专业大数据技术人员和大数据分析师这两种角色解耦。一个实时数仓中台,使用它的人并不需要了解里面的技术细节,并不需要知道Flink、Hive、Hadoop的技术细节,只要知道他们是干啥的就行。
基于以上,TIS改造之初并没有针对实时数仓进行进行编码,而是花了将近一年时间对TIS产品底座进行构建,着重进行了以下几方面构建:
插件仓库/热生效机制
现有行业中提供的工具栈,需要在后台系统中自行部署,例如:Chunjun的每个Connector实现子项目的项目描述文件pom.xml中都会有一个maven-assemble插件,通过它打包成一个独立包,
拷贝到目标节点的文件夹中进行部署,这对小白用户是有一定门槛的。
TIS简化了这一流程,在构建项目之时候会统一将第三方的依赖包进行打包,构建成TIS系统能够识别的TPI包存放到远端 仓库中,用户在TIS中可以查看到可用插件清单,如果需要,鼠标点中直接下载且热生效,就可以使用了。该操作体验和手机中安装App应用一样。

数据同步全流程建模
针对ETL的各流程进行建模,将可变因素进行抽象,抽取成一个TIS系统中的扩展点,统一归档到TIS的主工程中,在主工程中没有任何具体业务代码的实现,这样在进行具体业务逻辑实现 中不需要更改任何主工程的代码,这样在架构层面最大限度地贯彻了OCP原则。 例如如下是对ETL中,针对结构化(支持JDBC接口)和非结构化的数据源的执行流程图:

构建UI-DSL系统
随着整合进TIS的功能组件越来越多,需要为每一个组件都单独开发一套UI表单界面,为每一个属性定制输入框样式,为每个输入框开发输入合法性校验,可以想象这个工作量是巨大的。 而且,各自组件表单界面单独开发,很难保证在TIS中每个流程表单界面风格是统一的,且由于大量重复代码后期是很难维护的。另外,现在行业分工越来越细,一个流程基本上需要前端 开发工程师和后端开发工程师相互协作完成,可想而知这样的开发效率是相当低的。
由于TIS开发工程师都是有丰富经验后端开发者,大多对于前端方面的知识欠缺,因此,如何让这些没有前端开发经验后端开发工程师能够独立且畅快地完成一个UI组件的开发,成为一个重要的课题。
为此,TIS在底座中实现了一个UI-DSL系统,后端开发工程师使用JAVA语言编写一个表单对应的MetaData脚本,里面定义表单的布局,输入项的校验等信息,运行期 会自动将MetaData脚本渲染成前端的表单,从而完美解决了之前提到的问题。
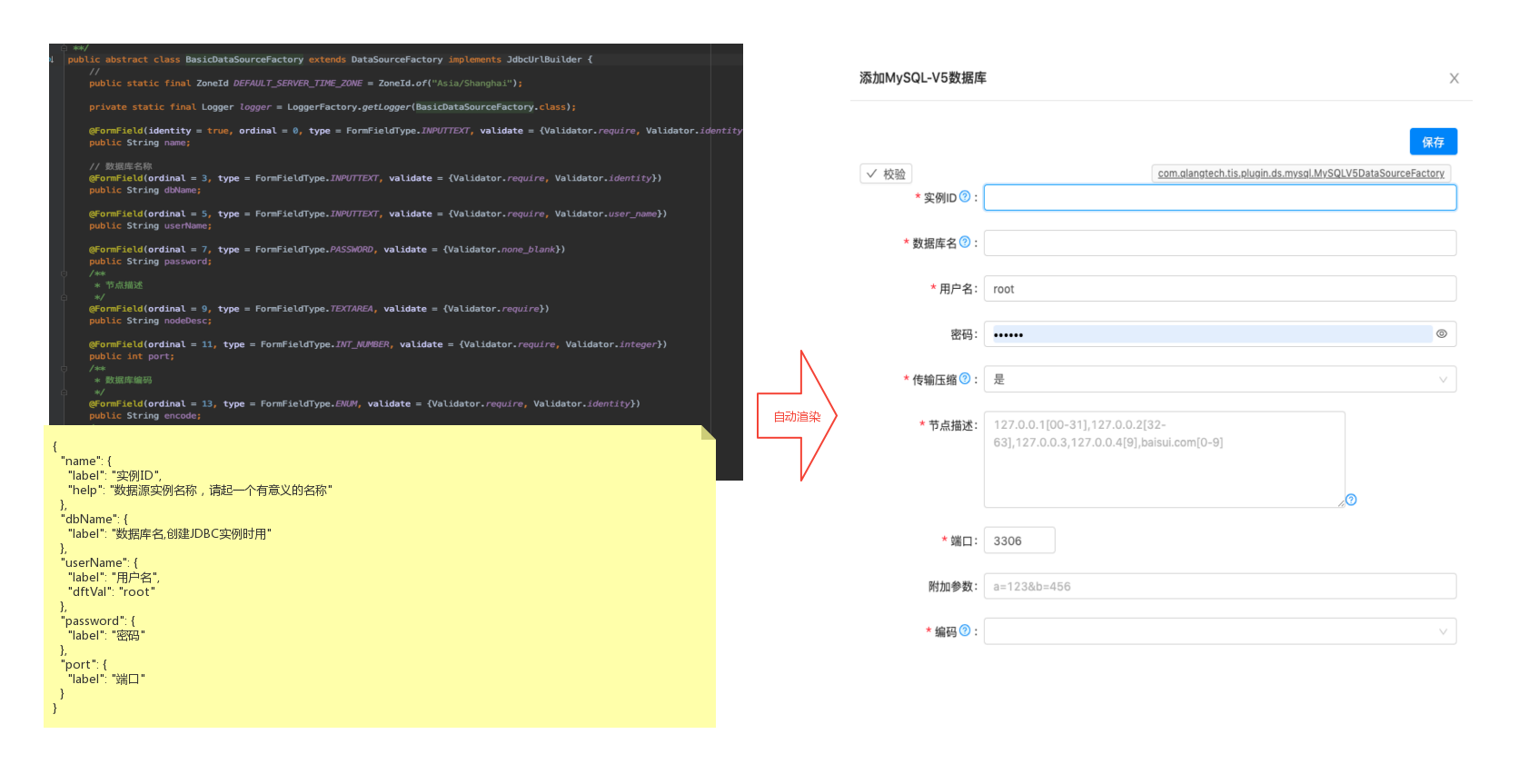
如上,是TIS中定义的MySQL数据源插件,只需要在对应POJO上为对应的属性添加FormFieldAnnotation标识,在配上字段对应的默认值、label等信息描述文件:
@FormField(ordinal = 3, // 表单中的排位顺序
type = FormFieldType.INPUTTEXT // 表单中控件类型
, validate = {Validator.require, Validator.identity}) // 输入项的校验规则
public String dbName;
{ "dbName": {
"label": "数据库名",
"help": "数据库名,创建JDBC实例时用"
}}
TIS是如何整合Chunjun
利用TIS元数据管理系统接管Chunjun流数据类型控制
Chunjun流处理中构建的RowData实例是通过目标端Jdbc MetaData自动生成的(用户不需要在JSON配置文件中设置),内部需要通过目标端(Source/Sink)字段JDBC中的元数据信息的fieldType作为参数来映射 flink的DataType实例,调用的接口是
com.dtstack.chunjun.converter.RawTypeConverter,
public interface RawTypeConverter {
DataType apply(String type);
}
在实际处理过程中发现,仅仅利用 JDBC col metaDatafieldType作为参数还是不够的, 例如:MySQL的表定义为bigint,int,smallint的整型,当用户添加unsigned修饰,bigint在Flink中的映射类型需要从BigIntType变成DataTypes.DECIMAL
原smallint类型需要变成IntType不然执行就会出错,另外像 Oracle的Jdbc内部实现了一套区别与Jdbc标准的类型规范oracle.jdbc.OracleTypes,当得到Oracle的类型之后需要归一化成Jdbc的类型java.sql.Types,不然没法正常执行。
类型映射虽然很简单,但由于Java是强类型语言,在流处理执行过程中稍有不慎就会出现ClassCastException,所以得格外小心地处理,因此TIS在Chujun中引入了一个新的类型抽象com.qlangtech.tis.plugin.ds.ColMeta
来封装Jdbc MetaData的列信息,在具体执行过程中可以更加细腻地控制Flink 内部的列类型了
public interface RawTypeConverter {
DataType apply(ColMeta type);
}
public class ColMeta implements Serializable {
public final String name;
public final DataType type;
public final boolean pk;
public ColMeta(String name, DataType type, boolean pk) {
this.name = name;
this.type = type;
this.pk = pk;
}
//...
}
public class DataType implements Serializable {
public final int type;
public final int columnSize;
public final String typeName;
// decimal 的小数位长度
private Integer decimalDigits;
public DataType(int type, String typeName, int columnSize) {
this.type = type;
this.columnSize = columnSize;
this.typeName = typeName;
}
/**
* is UNSIGNED
*/
public boolean isUnsigned() {
//...
}
}
取代基于JSON配置驱动的任务变为基于元数据模型驱动任务
有了TIS底层元数据关系管理的支持,数据同步的任务定义的大部分工作可以自动生成,用户只需要做一些辅助工作,例如,用户需要导入一个张表,表有10列,用户需要做的是辅助确认: 对于Source端确认表主键,Polling策略的轮询间隔时间及轮询列名,对于Sink端选取Insert的插入策略,这些都只需要点击鼠标就能完成,页面UI中的显示逻辑和Chunjun的规则相一致。
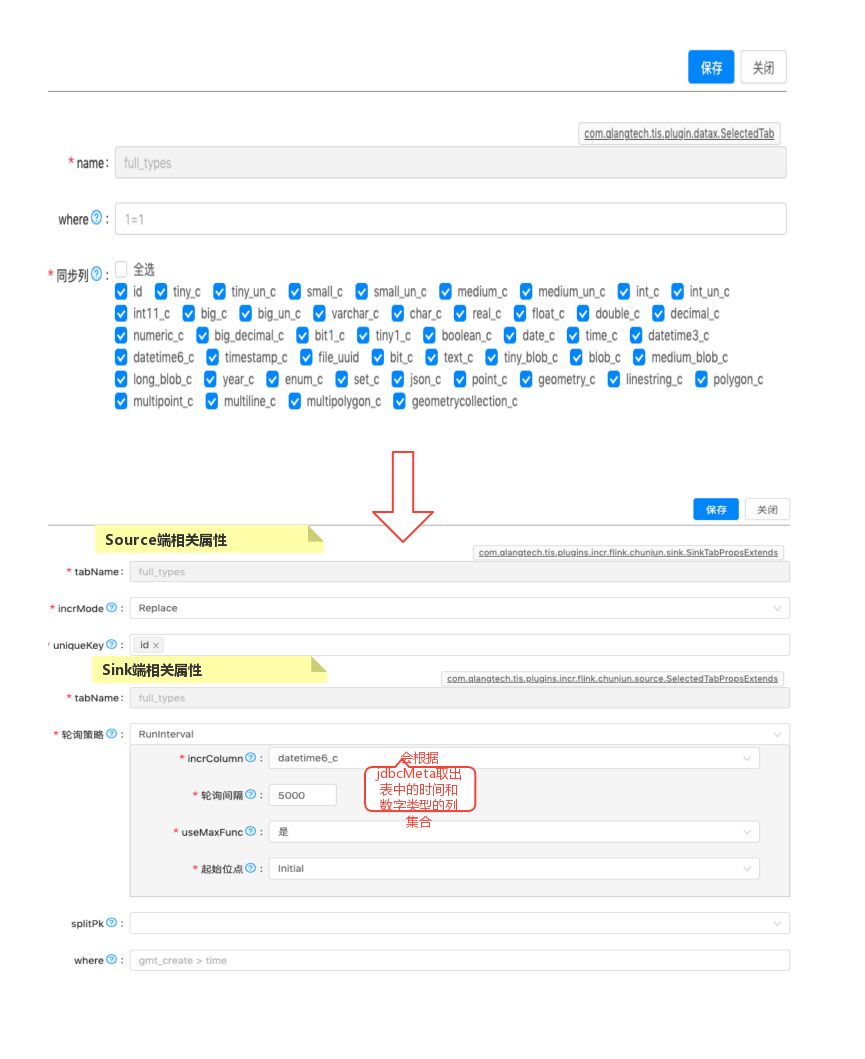
为Chunjun添加新的TIS扩展点
在v3.6.0版本为顺利地将Chujun Connector整合进TIS,需要添加几个两个功能扩展点,一是为增量Source端表的属性设置com.qlangtech.tis.plugins.incr.flink.chunjun.source.SelectedTabPropsExtends
,二是为Sink端表的属性设置com.qlangtech.tis.plugins.incr.flink.chunjun.sink.SinkTabPropsExtends
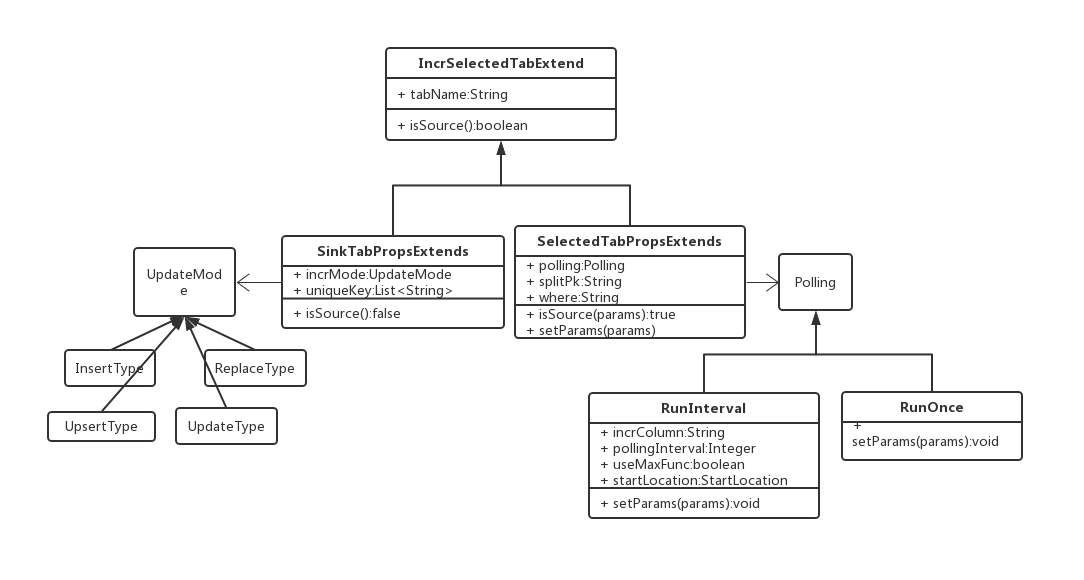
各司其职,繁荣生态
TIS的构建理念是坚决避免重复造轮子,必须站在行业的巨人的肩膀上,作大数据行业中优秀工具栈的粘合剂。TISv3.6.0alpha 有幸能按时发布得益于行业中有像Chunjun,DataX,Flink-CDC,Flink这样优秀的开源项目存在
,使得TIS整体可靠性得到保障。
特别要感谢Apache Flink,提供了一个强大的实时计算生态,Flink CDC和Chunjun,TIS都是生长在这个生态中的茁壮成长的小树苗,每个项目都专注于自己擅长的领域,且有相互补充。
临近发布,发现一个很有意思的使用场景,那就是用户可以选择基于Flink-CDC的MySQL Source插件来监听MySQL 表的增量变更,将数据同步到以 Chunjun 构建的 Sink中去,这样的混搭使用方式给用户带来了更多的选择自由度,也避免了 在Flink-CDC和Chunjun各自的框架内部重复造轮子从而造成生态内卷。
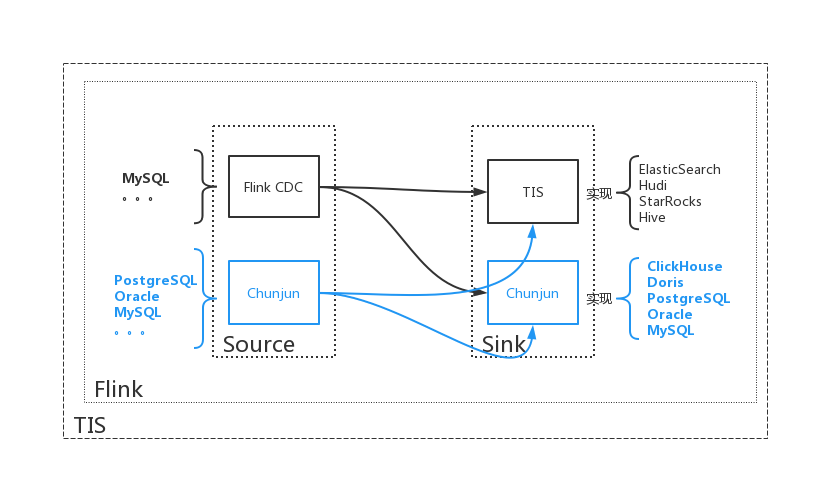
如上图,用户需要构建一个MySQL到Doris的实时数据通道,Sink是使用Chunjun实现的,Source端的实现可以选择Flink-CDC或者Chunjun的实现,两者有诸多区别用户可以根据自己业务特点,选择使用。
| 特性 | Chunjun | Flink-CDC |
|---|---|---|
| 同步实时性 | 因Polling轮训,略慢 | 近实时响应 |
| 资源使用 | 每个表对应一个线程进行监听 | 多表使用一个线程监听 |
| 支持物理Delete | 无法监听物理删除、更新(Insert和Update归一化为Upsert事件)事件 | 支持所有事件类型 |
| 表结构要求 | 表中必须要有一列标记记录更新时间(至少精确到秒)的时间戳列 | 无特殊要求 |
| 通用性 | 支持所有支持JDBC的数据源 | 只支持类似MySQL有binlog特性的数据库 |
上表的同步实时性对于Chunjun来说也有例外,例如MySQL 服务端支持查询流式导出功能,JDBC客户端初始化时设置参数FetchSize为Integer.MAX,就能启用流式数据导出,从响应更新实时性上来看已经达到近实时同步的效果
拥抱CloudNative
云原生(CloudNative)时代的到来为我们描绘了一副美好的画卷,对于终端用户来说提供了低成本、可靠的IT基础服务,可以专注于业务开发,这非常好。
但对于互联网技术从业者来说,似乎有隐忧,那就是互联网红利将会被阿里云这样的云厂商通吃,小厂商只有干瞪眼的份,那我们煞费苦心构建的像TIS这样的开源项目在云时代还有用武之地吗?其实这样的担心是多余的。
一个健康的生态,必须要保证生物多样性,生态中各个物种并不是独立,他们之间存在相互依存的关系。同样在大数据生态中如果只有像阿里云、亚马逊这样互联网大厂活得很滋润,并且构成了一个人才黑洞,把其他小厂的资源全部吸干了, 想必这样的生态也不可能长远。
从本质来说,促成任何个人或组织之间的合作都有一个前提,那就是存在比较优势,就如同瞎子背瘸子相互协助前行,国家之间的合作也是,中国具有廉价劳动力和广阔的市场与发达国家的技术优势进行互补,这种合作是可持续的。
云大厂可以把昂贵的互联网基础设置,用集约化采购的规模优势大大地降低成本,然后用技术手段将这些设备云化成IAAS服务提供给客户,小厂技术具有灵活高效与较低的技术人员薪资成本优势,以这种优势在IAAS之上构建PAAS服务
,类似任务调度,实时数仓非常合适。
国外已经有成功的案例,比如Snowflake提供的云原生实时数仓和亚马逊等云厂商之间的合作,有同学肯定会问:"为啥亚马逊不能自己搞一个像snowflake呢?",其实答案前面已经提到。
视频讲解
尝试TIS
TIS的最新版本 https://github.com/datavane/tis/releases/tag/v3.6.0-alpha