将数据变更同步到Kafka
场景介绍
众所周知,Apache Kafka的优势有吞吐量大、响应高效等特点。 正因如此,生产环境中,运维团队经常使用Apache Kafka作为消息转发工具来中转数据库变更消息,下游业务团队统一监听Kafka的Topic以做进一步消息处理。
这样做的好处是,数据运维团队可以统一控制数据库增量消息订阅出口,对下游业务统一做数据治理授权,另外,由于数据库的增量消息使用统一集中管理,避免了多个客户端同时监听数据库增量消息,从而降低了数据库负载 。

化繁为简
使用TIS来实现以上需求,整个流程简化成几个步骤,只需要轻点鼠标,不需要做额外过多设置就能将一个数据库中的全部表的变更消息同步到一个Kafka Topic中。
实现原理
TIS实时数据同步管道是基于Flink来实现的,Source端监听数据库增量事件的算子是基于Flink-CDC的,Kafka Sink是基于 Chunjun Kafka Connector来实现的,
TIS的优势在于整合,杜绝重复造轮子,致力于将开源社区优秀的框架工具无缝整合在一起提供给用户畅快地使用。
TIS为实现该场景需求,为了最大限度方便用户,特地做了如下定制:
Sink端支持 Stream API 和Flink SQL 两种脚本实现方式
SQL: 优点逻辑清晰,便于用户自行修改执行逻辑 Stream API:优点基于系统更底层执行逻辑执行、轻量、高性能
两种方式各有特点,用户可以根据自己需要进行选择
支持多种消息格式
在Flink官网中列出了消息中间件传输的多种消息格式,种类比较多 ,TIS选取了最常使用的两种消息格式:
canal-json和debezium-json在消息体中增加表名称
原生的Flink flink-formats 模块实现中 ,没有在消息体上添加被监听的表名属性,因此,用户往往会在Kafka中为数据库中每张表都单独构建一个与之对应的Topic以区分不同的表,这样做极大地浪费了Kafka的资源,并且难以维护。
TIS做了优化,只要同一个库的表,就向同一个Kafka Topic中写入,另外在消息体中添加表名,下游消费端就能通过表名属性区别不同的表了。
流程实操
本示例构建一个MySQL整库表变更消息同步到Kafka某一Topic的例子
准备工作
需要在本地环境中安装好以下几个组件:
Kafka集群
按照 文档 https://blog.csdn.net/lijiewen2017/article/details/127609875 中介绍,使用docker容器来简化 Kafka安装
TIS控制台
TIS Flink组件
准备一个MySQL 数据库实例
准备好一个MySQL5.7 版本的数据库,内有数据库表若干
操作步骤
基本信息配置
| 说明 | 图示 |
|---|---|
当完成 安装 步骤之后,进入TIS操作界面,点击菜单栏中实例链接 | 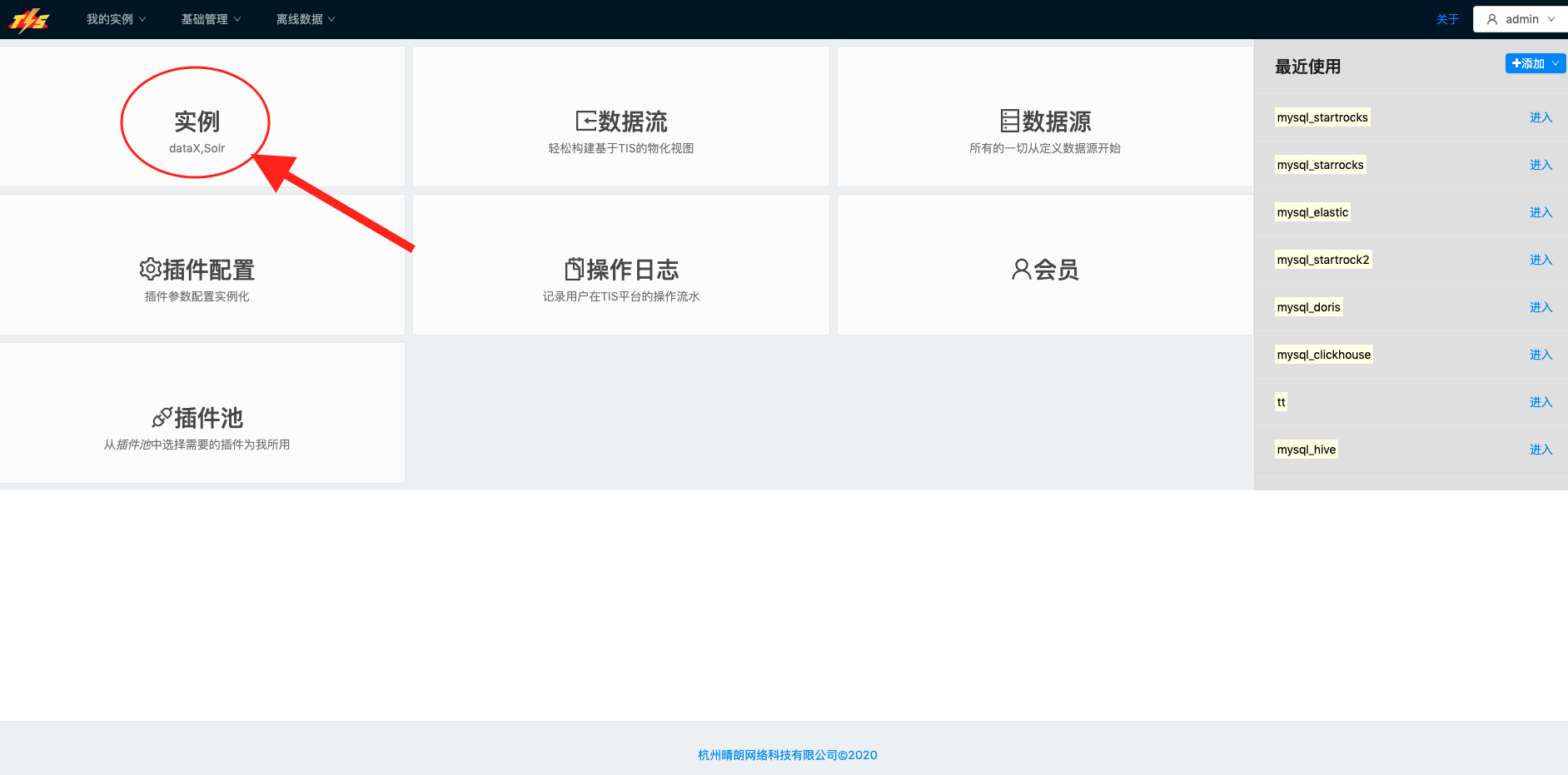 |
进入实例列表,点击右侧添加下拉按钮中的数据管道,进行MySQL端到Kafka端的数据同步通道构建 | 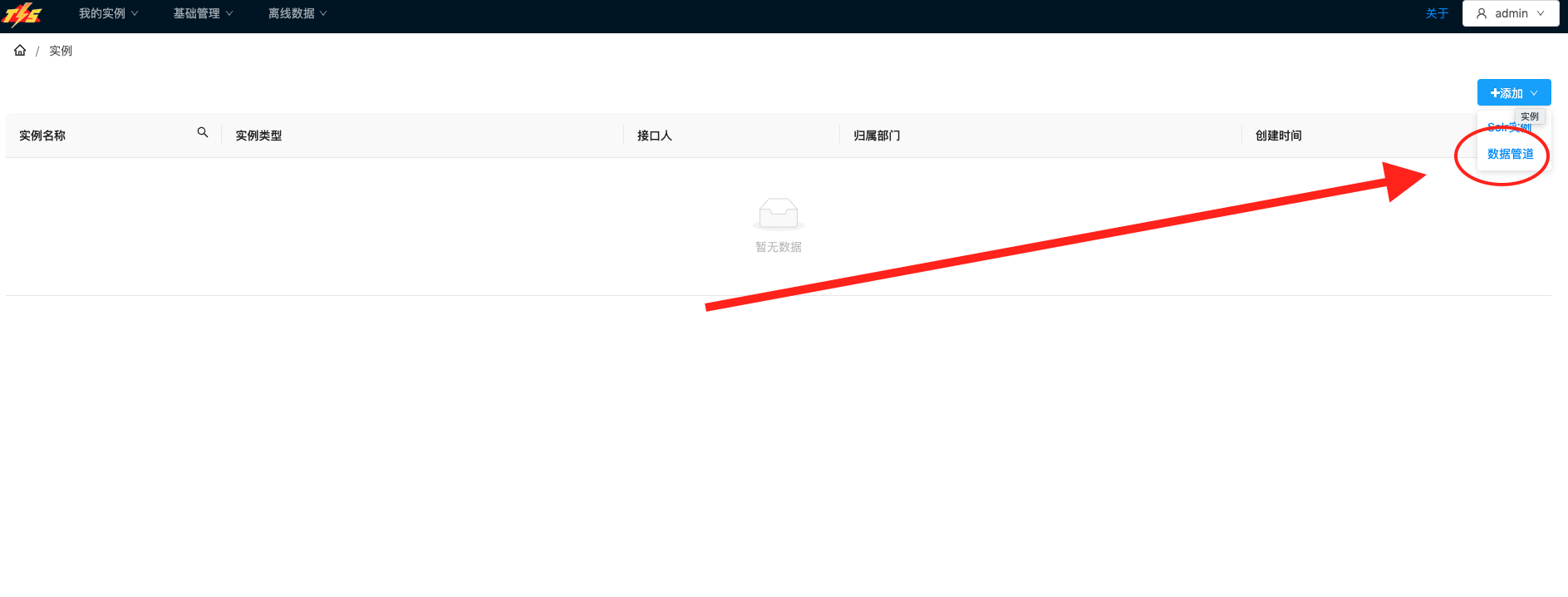 |
| 添加流程一共分为5步,第1步添加数据通道的基本信息 |  |
进入数据端选择步骤,选择Reader Writer类型选择,由于系统刚安装,数据端类型对应的插件(tis-datax-kafka-plugin,tis-ds-mysql-plugin)还没有选取,需要点击插件安装添加按钮,安装插件 |  |
插件安装完毕,将插件管理页面关闭 |  |
Reader端选择MySQL,Writer端选择Kafka,点击下一步按钮,进行MySQL Reader的设置 |  |
在Reader设置页面,点击数据库名项右侧配置下拉框中MySqlV5 数据源,完成表单填写,点击保存按钮,其他输入项目使用默认值即可,然后再点击下一步选取Reader端中需要处理的表 |  |
| 选择需要的表: 点击 设置按钮,对Kafka目标表设置,设置目标表的目标列等属性设置.点击 保存按钮,然后点击下一步,进入Kafka Writer表单设置 | 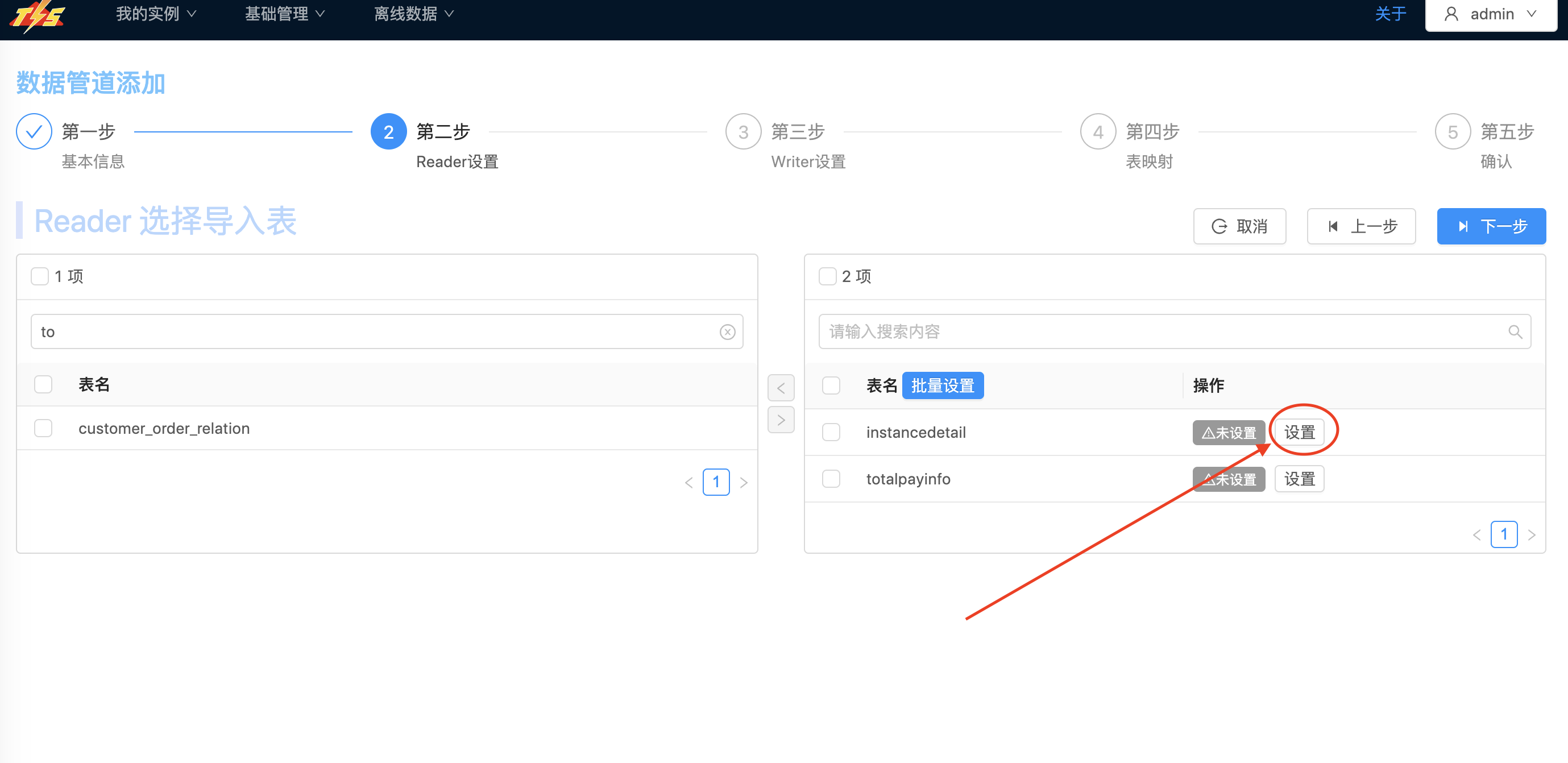  |
| Kafka Writer表单 1. 设置Kafka服务端 Bootstrap Servers地址及Topic配置 2.其他配置项按无特殊需求,按系统默认即可 3.点击进入下一步 |  |
| 确认页面,对上几步流程中录入的信息进行确认。 点击 创建按钮完成数据流通道定义 |  |
实时同步启用
| 说明 | 图示 |
|---|---|
| 接下来,开通实时增量通道 首先需要安装Flink单机版 安装说明 | 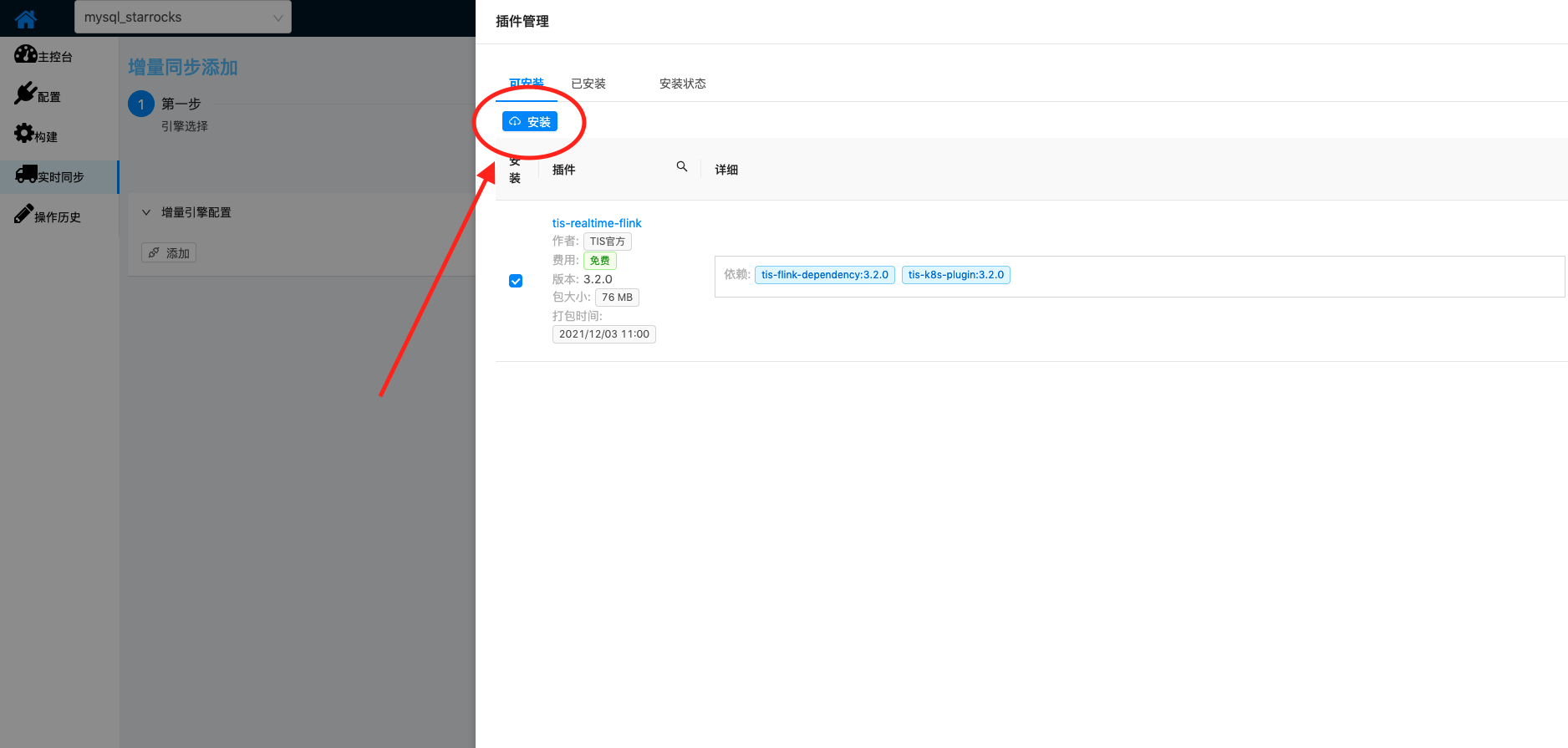 |
| Flink集群启动之后,在TIS中添加Flink集群对应配置 表单填写完成之后,点击 保存&下一步按钮进入下一步Sink,Source相关属性设置 | 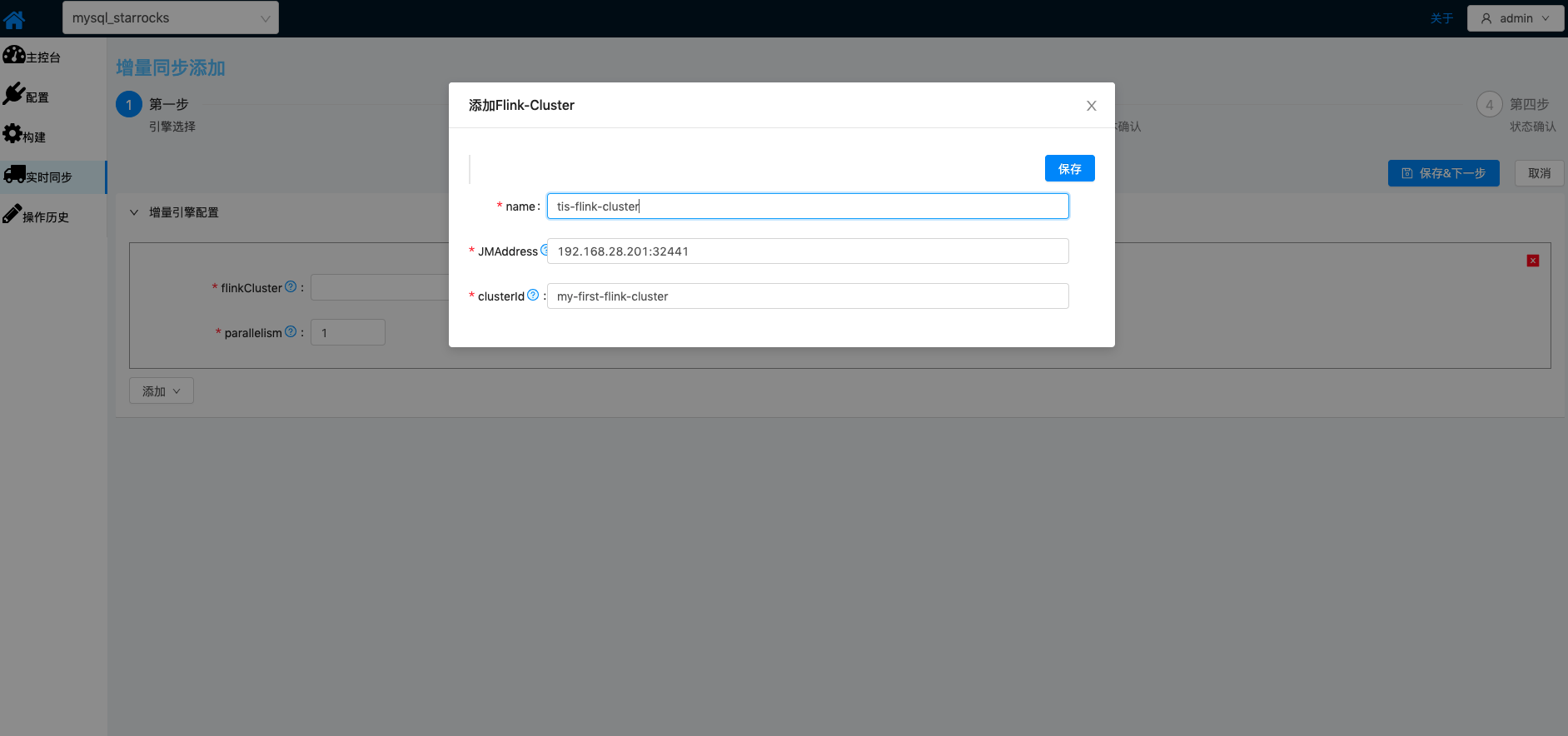  |
在该步骤,首先需要添加Sink端插件 tis-flink-chunjun-kafka-plugin |  |
| 添加Flink SourceFunction对应的flink-connector-mysql-cdc插件 和 Fink Sink对应的Kafka插件: 1.选择Kafka消息传输格式 2.选择flink 增量执行脚本 Flink SQL/Stream API 设置完成之后进入下一步 |  |
| TIS会解析Reader选取的表元数据信息,自动生成Flink Stream Code 在该版本中,自动生成的Flink Stream Code还不支持用户自定义编写业务逻辑 点击 部署按钮,进入向Flink Cluster中部署流处理逻辑 |  |
| 至此,MySQL与Kafka数据增量通道已经添加完成,MySQL到Kafka实时数据同步可以保证在毫秒级完成 |  |
测试确认
最后我们来验证MySQL库变更同步到Kafka的数据通道执行是否正常
首先,在Source端的数据库表上更新几条数据, 执行inert或者update SQL语句,例如:
update instancedetail set last_ver=last_ver+1 where instance_id = '1';
然后,打开Kafka客户端监听Topic接收到的消息是否正确:
启动Kafka客户端监听Test Topic的消息内容:
/opt/kafka_2.13-2.8.1/bin/kafka-console-consumer.sh --topic=test --bootstrap-server=192.168.28.201:9092
会在控制台中接收到如下,消息内容:
{"before":null,"after":{"instance_id":"1",
"order_id":"1",
"batch_msg":"","type":0,"ext":"","waitinginstance_id":"","kind":1,
"parent_id":"","pricemode":1,"name":"美味香酥鸡","makename":"","taste":"",
"spec_detail_name":"","num":1,"account_num":1,"unit":"份","account_unit":"",
"price":32,"member_price":99,"fee":32,"ratio":1E+2,"ratio_fee":32,"ratio_cause":"",
"status":2,
"addition_price":0,"has_addition":0,"seat_id":""},
"op":"c",
"source":{"table":"instancedetail"},
"ts_ms":1683779944246}
符合预期
总结
本文档就MySQL同步Kafka作为例子进行说明,整个方案实现基本上达到了开箱即用,只需用户做简单设置就能把同步实例构建起来。
其实作为Source和Sink端的类型,在TIS中是可以随意切换的,例如,可以将MySQL换成SQLServer、Oracle等其他连接器,Sink端也可以使用RabbitMQ ,RocketMQ等其他MQ实现,实现流程与MySQL同步Kafka的实现方式基本一致。
希望通过本例的说明,起到抛砖引玉,举一反三的效果。还等什么呢? 赶紧下载TIS,在自己本地环境试试吧。