
前言
说到依赖反转原则 ,百度百科是这样介绍的,如下:
在面向对象编程领域中,依赖反转原则(Dependency inversion principle,DIP)是指一种特定的解耦(传统的依赖关系创建在高层次上,而具体的策略设置则应用在低层次的模块上)形式,使得高层次的模块不依赖于低层次的模块的实现细节,依赖关系被颠倒(反转),从而使得低层次模块依赖于高层次模块的需求抽象。
大家应该会马上会联想到Spring Framework,在介绍Spring Framework框架常常会提及依赖反转原则,看上面的介绍估计会云里雾里,说得通俗一点,该原则的初衷要求服务提供者与服务调用者在代码实现层面实现解耦。
为了加深理解,经常会提到的一个例子,以前古时候的包办婚姻,假如是男方到了适婚年龄,只要把自己的条件、要求告诉媒婆。接下来找合适对象的过程就交给媒婆就行了,男方只需要负责到时候入洞房就行了。对于男方来说, 婚姻和他是服务提供者和消费者的关系,由于引入了媒婆的角色,男方省去了谈婚论嫁的麻烦过程,只需要专注于核心业务-入洞房。最终使得整个过程显得简单高效,形式格外优雅。
因此,依赖反转原则DIP作为一个朴素的原则存在,可以应用到软件设计领域每一个流程环节当中,而不仅仅适用于Spring Framework当中。
本文就以依赖反转原则DIP在TIS增量实时数据通道的设计、实现过程中如何利用这一原则来优化设计、实现流程进行阐述。
实现实时增量数据管道需求
在TIS中为用户提供了基于Flink端到端的实时增量数据通道功能,市面上已经提供了基于Flink和Flink-CDC的实时流同步工具,从用户反馈来看已经很方便了,那为什么还要通过TIS来 使用Flink-CDC呢?
这是一个非常好的问题,要回答这个问题,首先我们需要从用户的角度了解用户到底需要什么?然后从需求出发设计并且构建出用户体验达到极致的产品。
大数据流计算领域,用户的核心需求是:
- 可追溯操作历史的控制系统,这样可以方便回滚历史操作。
- 不关心算子实现细节,流计算的使用者往往是对Flink不了解的数据分析人员,所以在产品使用体验上需要屏蔽底层技术细节。
- 可扩展的端类型:Flink-CDC从3.0版本支持的Connectors,只支持了有限个数的基于增量监听CDC技术的Source端 ,和少量Sink端实现,如:Doris和StarRocks的Sink端类型。还远远没有达到用户实际生产场景下的端类型。所以,需要提供在更高层次上,通过便捷方式扩展Source和Sink端类型的手段。
TIS正式为了弥补以上三个使用Flink-CDC框架中的不足而开发的。
具体实现
下面具体对以上第2点进行进行说明,配置并且触发执行基于Flink-CDC的数据管道具体通过以下步骤完成
在构建DataStreamSource步骤中,通过调用Flink-CDC提供的API代码,可以方便订阅到如MySQL的增量更新消息,如下代码:
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.databaseList("yourDatabaseName") // set captured database, If you need to synchronize the whole database, Please set tableList to ".*".
.tableList("yourDatabaseName.yourTableName") // set captured table
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// enable checkpoint
env.enableCheckpointing(3000);
env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// set 4 parallel source tasks
.setParallelism(4)
.print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute("Print MySQL Snapshot + Binlog");
}
通过以上流计算的流程中可以使用创建出MySqlSource<String> mySqlSourceSource加入到各种算子中去进行计算。
使用SQL的方式将Stream Source 注册为Flink Table:
CREATE TABLE mysql_source (...) WITH (
'connector' = 'mysql-cdc',
'scan.startup.mode' = 'earliest-offset', -- Start from earliest offset
'scan.startup.mode' = 'latest-offset', -- Start from latest offset
'scan.startup.mode' = 'specific-offset', -- Start from specific offset
'scan.startup.mode' = 'timestamp', -- Start from timestamp
'scan.startup.specific-offset.file' = 'mysql-bin.000003', -- Binlog filename under specific offset startup mode
'scan.startup.specific-offset.pos' = '4', -- Binlog position under specific offset mode
'scan.startup.specific-offset.gtid-set' = '24DA167-0C0C-11E8-8442-00059A3C7B00:1-19', -- GTID set under specific offset startup mode
'scan.startup.timestamp-millis' = '1667232000000' -- Timestamp under timestamp startup mode
...
)
以上是Flink-CDC提供的标准化的Demo案例。
在这里我们重新用依赖反转原则来思考一下,这个构建流程是否有违背该原则?确实,从用户的角度来说,用户只关心最终构建出来的MySqlSource<String>实例,至于构建该实例的过程用户并不关心,所以在设计过程需要将
MySqlSource<String>实例构建过程与它的调用者之间进行解耦合。
是时候发挥TIS的作用了,TIS需要发挥实例容器的作用,由TIS根据用户配置的Source端参数自动地创建MySqlSource<String>实例,
在运行时自动注入到执行流程中。
- 配置Source/Sink Connector

- 直接引用TIS注入的SourceStream实例

- 当用户选择Flink SQL类型脚本,直接引用已经注册完成的Table名即可
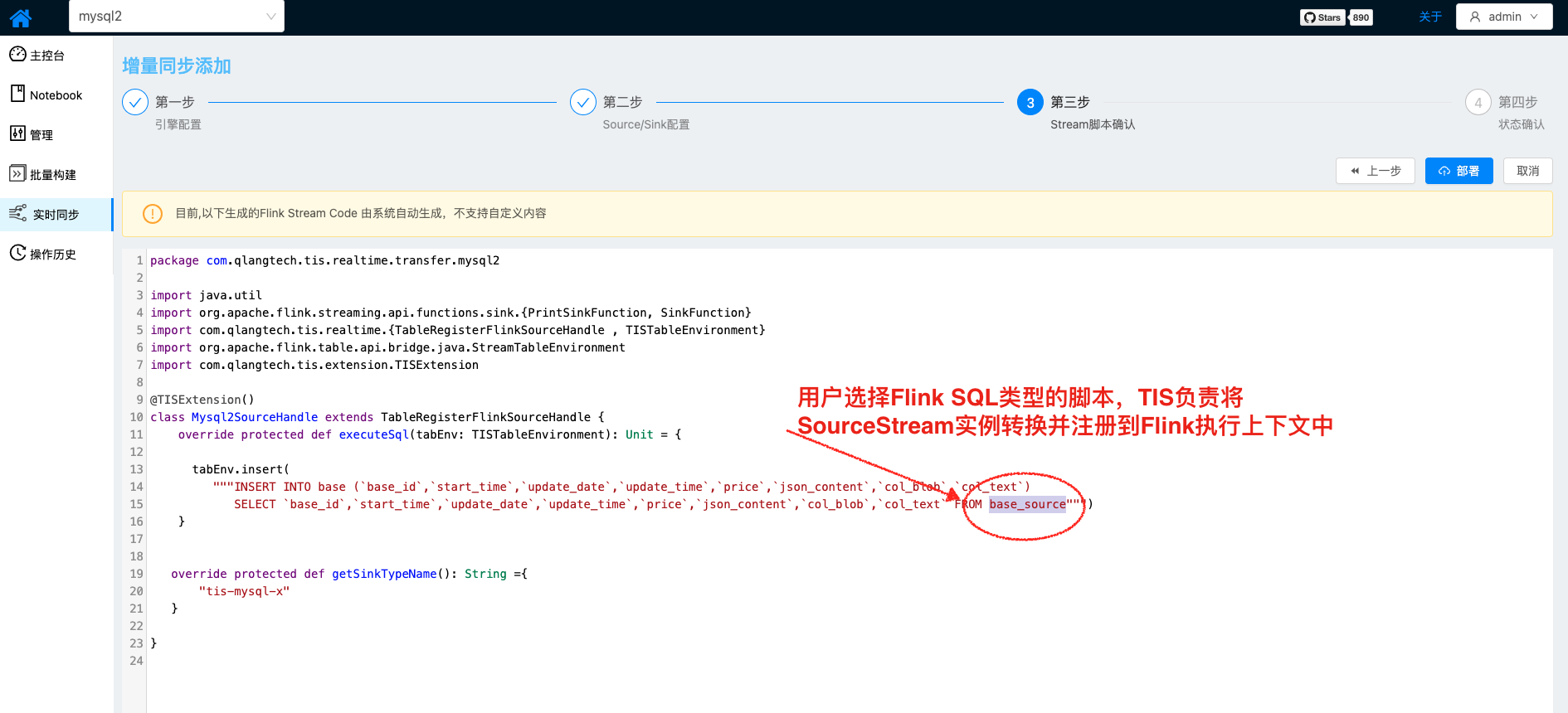
以上具体提供注入实例的封装工厂是:
- 执行Stream Source创建: FlinkCDCMySQLSourceFactory.java
- 执行将Stream Source转成Flink Table: MySQLDynamicTableFactory.java
以上两段代码的执行逻辑类似Spring FactoryBean 执行逻辑,实现容器预定的扩展工厂接口,运行期由容器负责初始化,继而将实例注入到需要反向依赖的实例中。
总结
本文介绍了利用依赖反转原则在TIS中实现实时增量通道的优化方法,可使最终用户最大限度地关注流式计算核心业务本身,其他的琐碎的与实例初始化相关的工作都交给TIS来完成即可。
与此类似的功能优化,在TIS实现过程中还有很多,会在日后的博客分享中陆续发表。