TIS Pipeline AI Agent - 让数据管道听懂人话
引言:告别复杂配置,拥抱对话式创建
在传统的数据集成工作中,创建一条数据同步管道往往意味着:
- 🔍 繁琐的插件选择: 在数十个 Reader/Writer 插件中查找合适的组件
- ⚙️ 复杂的参数配置: 填写数据库连接、表结构、字段映射等大量参数
- 🐛 反复的调试验证: 配置错误需要不断修改、重试
- 📚 陡峭的学习曲线: 新手需要阅读大量文档才能上手
现在,这一切都将改变。
TIS v5.0 正式推出 Pipeline AI Agent —— 一个革命性的对话式数据管道创建工具。您只需要用自然语言描述需求,AI Agent 就能自动完成插件选择、参数配置、管道创建的全过程。
就像这样简单:
👤 用户: 请帮我创建一个从MySQL库test_db到Paimon的数据同步管道,
同步orders和customers两张表,需要开启实时增量同步。
🤖 AI Agent: 我已经理解您的需求,正在为您创建管道...
✅ 已检测到MySQL Reader插件
✅ 正在安装Paimon Writer插件...
✅ 正在配置源端MySQL连接...
✅ 正在配置目标端Paimon存储...
✅ 已选择orders和customers表
✅ 批量同步任务已触发
✅ 增量实时同步已启动
您的数据管道已创建完成! 🎉
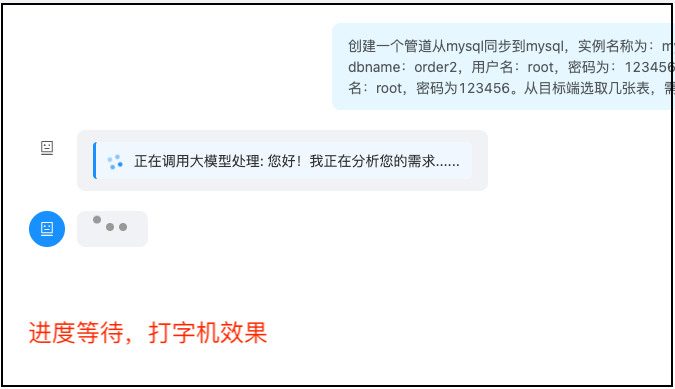
下图是TIS Pipeline AI Agent 聊天界面总览:
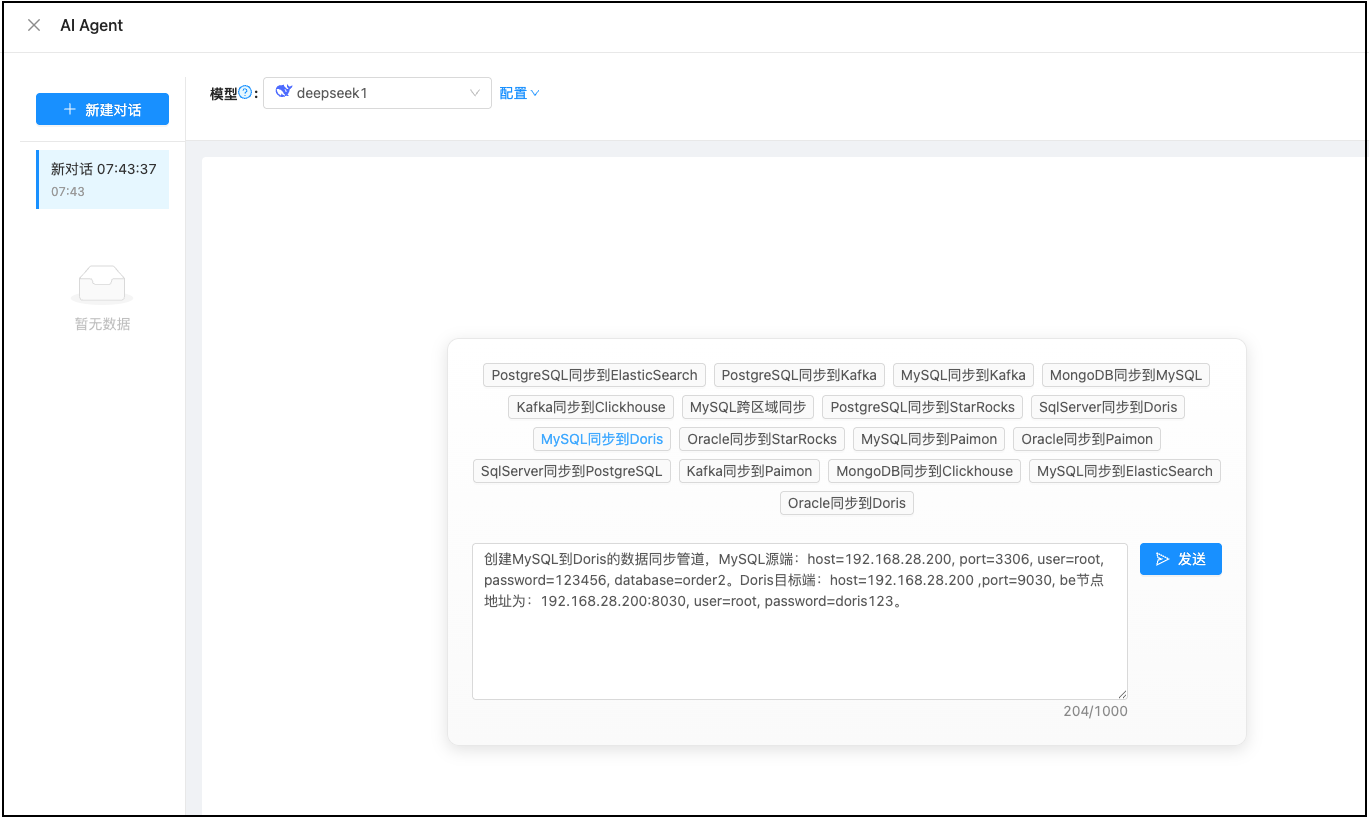
产品亮点:国内首个大数据原生 Pipeline AI Agent
🎯 国内首创,专为大数据领域打造
TIS Pipeline AI Agent 是国内首个专门针对大数据集成场景设计的原生 AI Agent 工具。不同于通用的工作流自动化平台(如 dify、n8n),TIS AI Agent 深度理解数据管道的业务逻辑和技术细节。
🚀 完全自主实现,深度整合
- 自主研发架构: 基于 Plan-and-Execute 模式,完全自主设计实现
- 深度整合插件体系: 原生支持
- 领域知识内置: 内置数据集成最佳实践,智能推荐配置方案
🧠 智能推理,自主决策
采用 Plan-and-Execute 架构:

- Plan 阶段: 用户输入一段构建数据管道的自然语言,通过LLM REST API理解用户意图,生成结构化执行计划
- Execute 阶段: 逐步执行任务,用户在管道描述中往往不能将TIS需要的配置参数列举齐全,agent执行器根据判断需要中断打开对话框,让用户输入完全后能继续执行任务
- 反馈循环: 实时反馈执行进度,支持中断和恢复
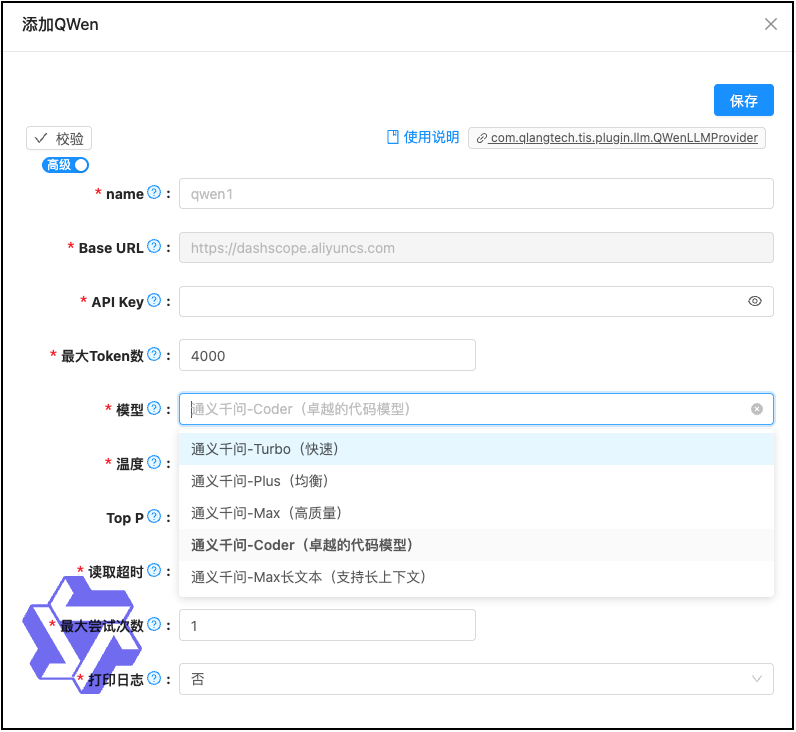
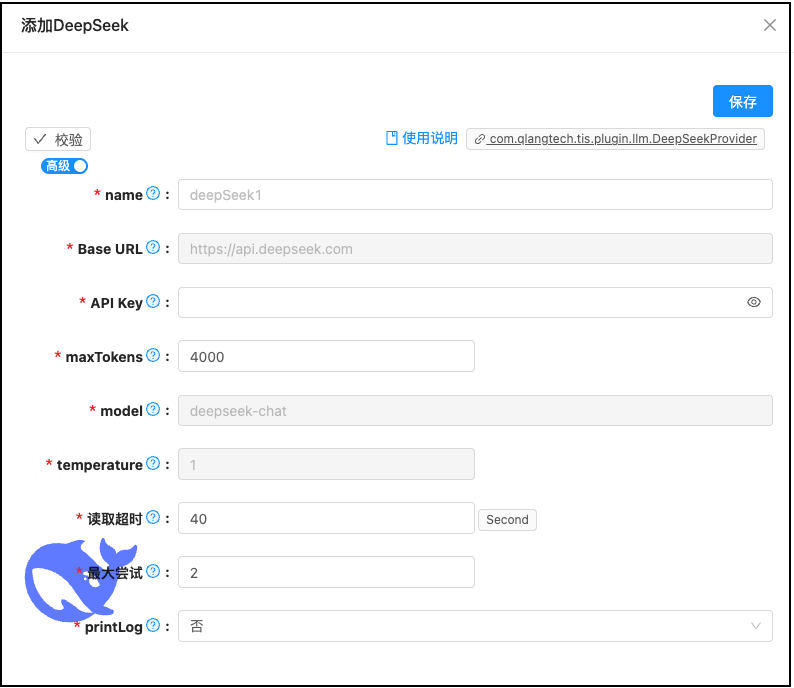
🤖 多模型支持,国产优先
- ✅ DeepSeek: 高性价比的国产大模型,推理能力强大
- ✅ 通义千问: 阿里云大模型,稳定可靠
- ✅ 可扩展支持更多 LLM 提供商
目前Pipeline AI Agent 支持以上DeepSeek和通义千问两个模型,测试下来这两个模型,从输入输出一致性上来说区别不大,都能按照Prompt提示词生成与预期一致的结果。不过从响应速度和费用上来说有明显的不一致
- DeepSeek: 响应速度明显比通义千问模型要慢,不过他的好处是便宜百万token才几毛钱,属于可以随意挥霍型的。
- 通义千问: 使用千问的“通义千问-Coder”模型,响应速度比较块,准确性也比较高,不过他的Tokens费用也比DeepSeek要高不少,百万token需要
TIS非常推荐使用 通义千问,在多个场景测试中,他比DeepSeek有更快的响应速度,以及能够智能地分析用户输入自然语言
⚡ 实时交互,极致体验
SSE (Server-Sent Events) 技术: 服务端实时推送执行状态
打字机效果: 逐字显示 AI 响应,自然流畅
进度可视化: 插件安装、任务执行进度实时呈现
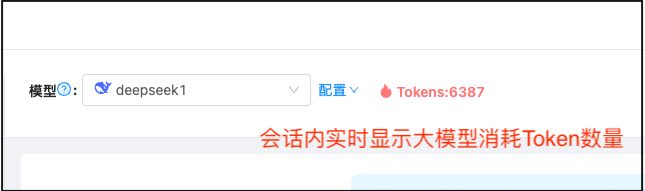
Token 计数: 实时统计 LLM Token 消耗,成本透明
实时交互界面 - 显示Token计数器、进度条、打字机效果展示
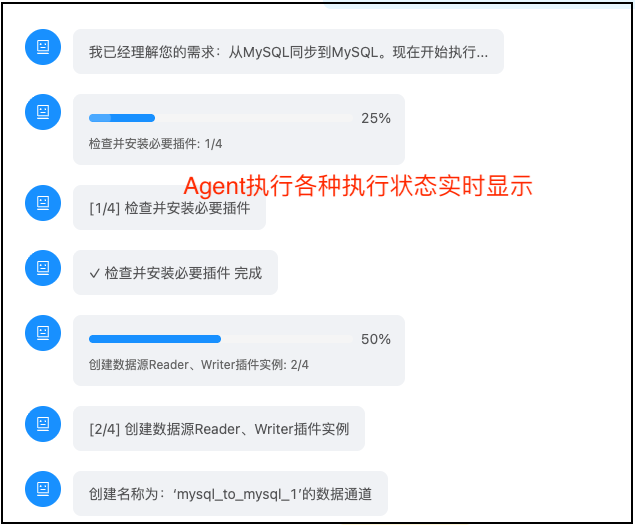

核心功能:从对话到管道的完整闭环
1️⃣ 自然语言理解与任务规划
功能描述: 用户用自然语言描述需求,AI Agent 自动识别:
- 📊 源端类型: MySQL、PostgreSQL、Oracle、MongoDB 等
- 📊 目标端类型: Paimon、Doris、ClickHouse、Elasticsearch 等
- 📋 同步表: 表名称列表或模糊匹配规则
- ⚙️ 执行模式: 仅批量同步 / 批量+增量实时同步
示例对话:
👤 用户: 我想把PostgreSQL的sales_db库中所有以report_开头的表同步到ClickHouse
🤖 AI: 我已经理解您的需求:
- 源端: PostgreSQL 数据库 (sales_db)
- 目标端: ClickHouse
- 同步表: 所有以 report_ 开头的表 (将在后续步骤让您选择)
- 执行模式: 默认批量同步 (如需实时增量请告知)
正在为您生成执行计划...
2️⃣ 智能插件检测与自动安装
功能描述: 根据识别出的源端和目标端类型,AI Agent 自动:
- 检查必需插件是否已安装
- 如未安装,自动从插件中心下载
- 实时推送安装进度和状态
- 安装失败自动重试或提示用户
支持的插件类型:
- Reader 插件: DataxMySQLReader、DataxPostgreSQLReader、DataxOracleReader 等
- Writer 插件: DataxPaimonWriter、DataxDorisWriter、DataxClickHouseWriter 等
- 增量监听插件: FlinkCDCMySQLSourceFactory、MongoDBCDCListenerFactory 等
- 增量写入插件: PaimonSinkFactory、DorisSinkFactory 等
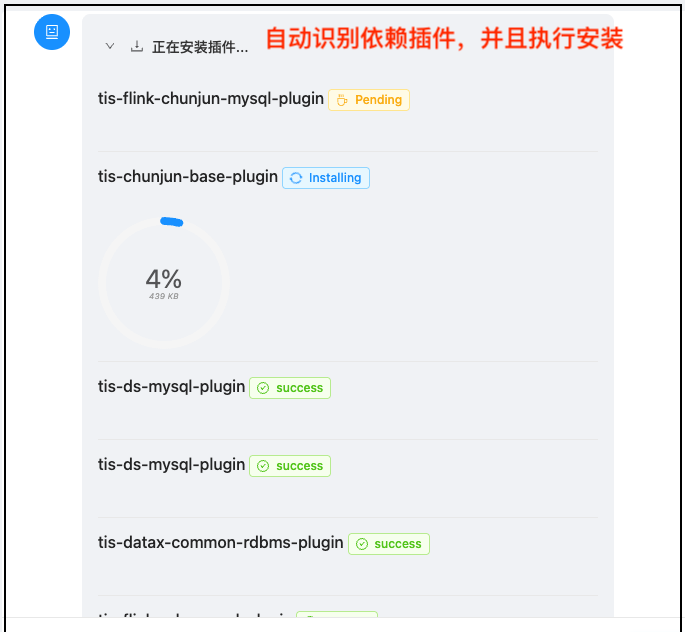

技术细节:
- 多插件安装,使用并发下载多个插件,提升安装速度
- 插件安装状态可展开/收起,避免界面拥挤
- 安装完成后自动收缩消息,保持界面清爽
3️⃣ LLM 辅助参数生成与智能补全
功能描述: 创建 Reader/Writer 插件实例时,AI Agent 会:
- LLM 智能推断: 根据用户输入和插件描述,自动生成配置参数
- 参数验证: 检查必填字段是否完整
- 人工补全: 如缺少必填参数(如数据库密码),弹出配置对话框请用户填写
- 倒计时机制: 配置请求默认等待 5 分钟,超时自动取消
参数补全流程:
🤖 AI: 正在生成MySQL Reader配置...
[LLM自动推断] 已生成以下参数:
- host: 从用户描述中提取
- port: 默认3306
- database: test_db
- username: 从上下文推断
❌ password: 缺失 (需要用户提供)
[弹出配置对话框]
请补充以下参数:
🔑 数据库密码: [______] (必填)
⏱️ 剩余时间: 4分58秒
插件配置补全对话框 - 显示已自动填充的字段和需要用户补充的字段,以及倒计时
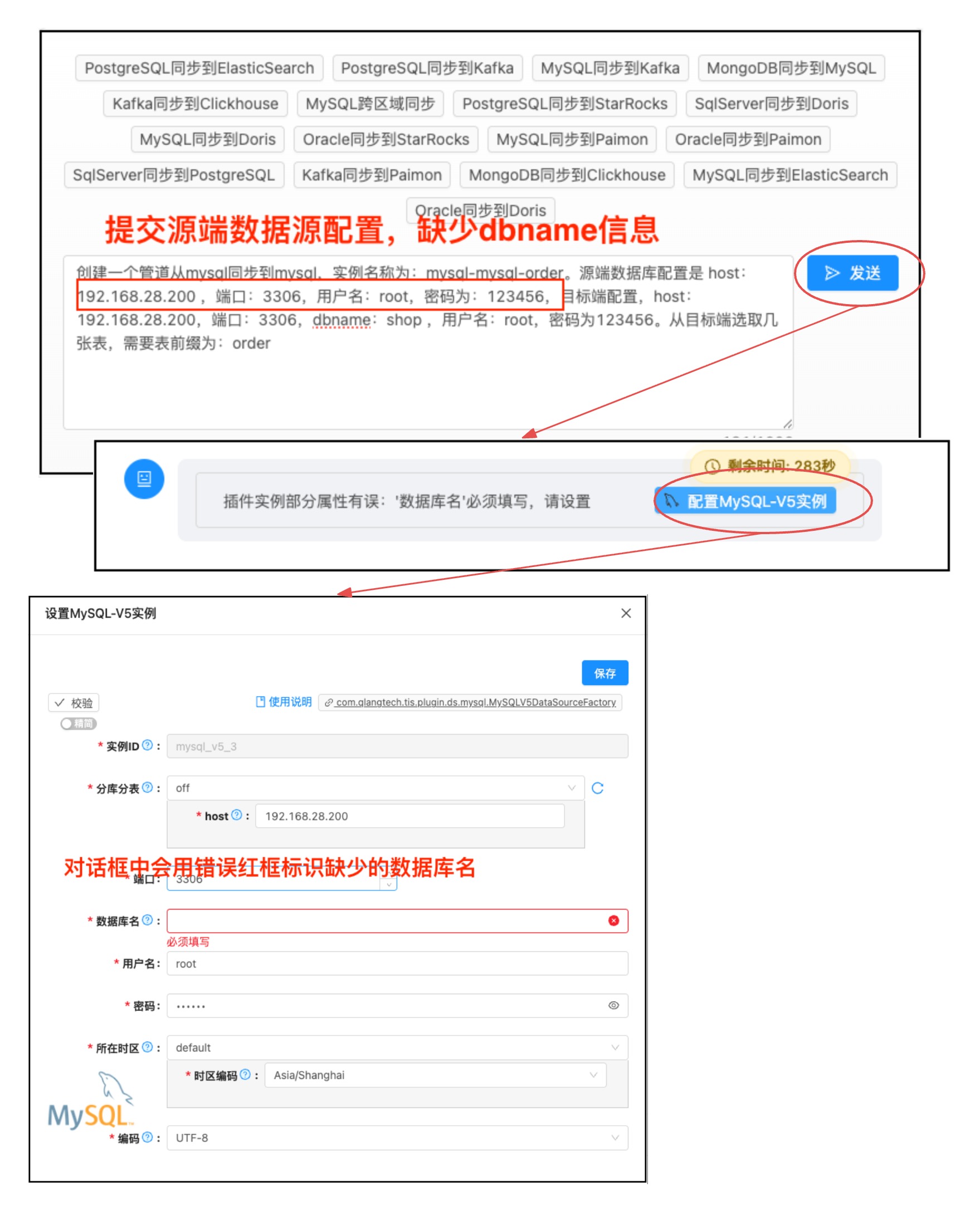
技术亮点:
- 智能字段提取: LLM 从自然语言中提取结构化参数
- 上下文记忆: 同一会话中复用已提供的信息(如数据库连接)
4️⃣ 可视化表选择与结构映射
功能描述:
- 如果用户未明确指定同步表,AI Agent 会弹出表选择对话框
- 用户可以可视化地勾选需要同步的表
- 支持批量选择、模糊搜索、正则匹配
- 自动加载表结构信息,供后续映射使用
表选择对话框 - 显示数据库中所有表的列表,支持多选和搜索过滤
5️⃣ 批量同步 + 增量实时双模式
批量同步:
- 全量同步历史存量数据
- 基于 DataX 引擎,高性能并行执行
- 支持断点续传和失败重试
增量实时同步:
- 基于 Flink CDC 技术,监听数据库 Binlog/WAL
- 实时捕获 INSERT、UPDATE、DELETE 事件
- 毫秒级延迟,准实时同步到目标端
一键启动流程:
Agent 执行过程中会询问是否要立即触发批量和增量实时数据同步任务
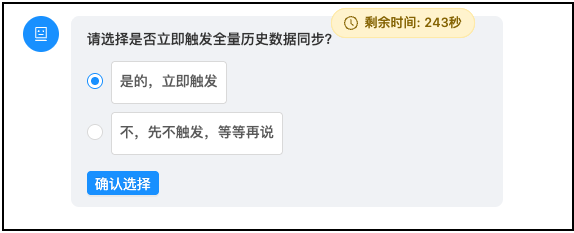

用户确认 需要启动增量实时 会确认TIS中是否已经部署了Flink执行引擎,如果还未部署会自动启动flink Standalone在本地自动安装

6️⃣ 任务中断与恢复
支持场景:
- ✅ 用户主动取消执行中的任务
- ✅ 超时自动取消(配置请求5分钟超时)
- ✅ 错误自动暂停,询问是否继续
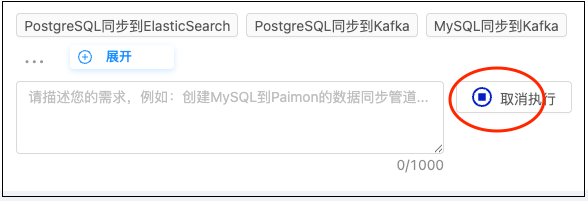
中断机制:
- 点击"取消执行"按钮,立即停止 AI Agent 任务
- 关闭 SSE 连接,释放服务端资源
- 所有待响应的配置请求标记为"已取消"
取消执行按钮 - 在任务执行过程中,发送按钮变为取消执行按钮
技术优势:领先的架构设计
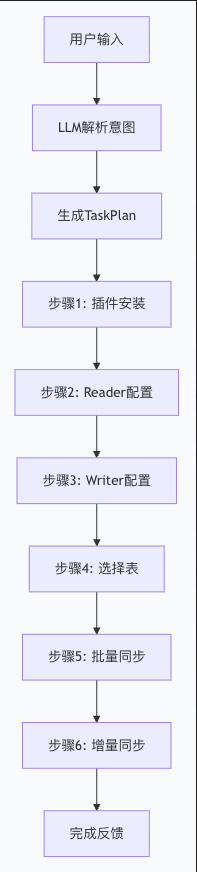
🏗️ Plan-and-Execute 架构
传统工作流 vs AI Agent:
| 对比维度 | 传统工作流 | TIS AI Agent |
|---|---|---|
| 任务规划 | 人工预定义固定流程 | LLM 动态生成执行计划 |
| 错误处理 | 失败即停止,需人工介入 | 自动重试或询问用户 |
| 灵活性 | 流程固定,难以应对变化 | 根据实际情况动态调整 |
| 学习成本 | 需要学习配置语法 | 自然语言即可使用 |
执行流程:
⚡ SSE 实时推送
为什么选择 SSE:
- ✅ 服务端主动推送,无需客户端轮询
- ✅ 原生支持断线重连
- ✅ 实现简单,浏览器原生支持
- ✅ 适合单向数据流场景
推送事件类型: tis-web-start-api/src/main/java/com/qlangtech/tis/datax/job/SSERunnable.java
| 事件类型 | 说明 | 示例数据 |
|---|---|---|
AI_AGNET_MESSAGE | 普通文本消息 | "正在生成配置..." |
AI_AGNET_PLUGIN | 插件配置请求 | 弹出配置对话框 |
AI_AGNET_SELECTION_REQUEST | 用户选择请求 | 选择插件实现 |
AI_AGNET_SELECT_TABS | 选择表请求 | 选择同步表 |
AI_AGNET_PLUGIN_INSTALL_STATUS | 插件安装进度 | 下载进度 80% |
AI_AGNET_LLM_CHAT_STATUS | LLM调用状态 | Start / Complete / ERROR |
AI_AGNET_PROGRESS | 任务进度 | 已完成 3/10 步 |
AI_AGNET_TOKEN | Token消耗统计 | 累计消耗 1234 tokens |
AI_AGNET_ERROR | 错误消息 | 数据库连接失败 |
🔄 阻塞式等待 + 超时机制
设计思路:
- AI Agent 执行到需要用户输入时,后端线程阻塞等待用户响应
- 每个请求有唯一
requestId,用于匹配用户提交的数据 - 默认等待 5 分钟,超时自动取消并通知用户
- 支持任务取消,唤醒所有等待线程
核心代码逻辑:
public <T extends ISessionData> T waitForUserPost(
RequestKey requestId,
Predicate<T> predicate
) {
Object lock = selectionLocks.computeIfAbsent(
requestId.getSessionKey(),
k -> new Object()
);
synchronized (lock) {
long startTime = System.currentTimeMillis();
while (!cancelled) {
T sessionData = getSessionData(requestId);
if (predicate.test(sessionData)) {
return sessionData; // 用户已提交,返回数据
}
long remainingTime = maxWaitMillis -
(System.currentTimeMillis() - startTime);
if (remainingTime <= 0) {
throw new TisException("操作已经超时");
}
lock.wait(remainingTime); // 阻塞等待或超时
}
}
}
🎯 智能参数匹配
插件能力自动匹配:
- 根据端类型 (EndType) 自动查找对应的插件实现
- 支持多实现选择(如 MySQL Reader 有多个版本)
- 自动处理插件依赖关系(如 Paimon 需要 HDFS + Hive)
参数提取流程:
- 获取插件的 JSON Schema 描述
- 发送给 LLM,结合用户输入生成参数
- 验证必填字段完整性
- 缺失字段请用户补全
📊 Token 消耗统计
- 实时统计每次 LLM 调用的 Token 消耗
- 界面顶部显示累计 Token 数
- Token 增加时显示火焰动画效果
- 帮助用户控制成本
快速上手:5分钟创建第一个管道
前置准备
1. 配置 LLM 提供者
在使用 AI Agent 之前,需要先配置大模型:
- 进入 TIS 管理界面,点击顶部导航栏的"系统设置"
- 选择"AI Agent 配置"
- 选择 LLM 提供者 (推荐 DeepSeek 或 通义千问)
- 填写 API Key 和相关配置
- 点击"测试连接"验证配置是否正确
推荐配置:
| 提供者 | 优势 | API Key 获取 |
|---|---|---|
| DeepSeek | 高性价比,推理能力强 | https://platform.deepseek.com |
| 通义千问 | 阿里云生态,稳定可靠 | https://dashscope.aliyun.com |
2. 准备数据源信息
确保您手头有以下信息:
- ✅ 源端数据库连接信息 (主机、端口、用户名、密码、库名)
- ✅ 目标端数据库连接信息
- ✅ 需要同步的表名称
- ✅ 是否需要实时增量同步
第一个管道:MySQL → Paimon
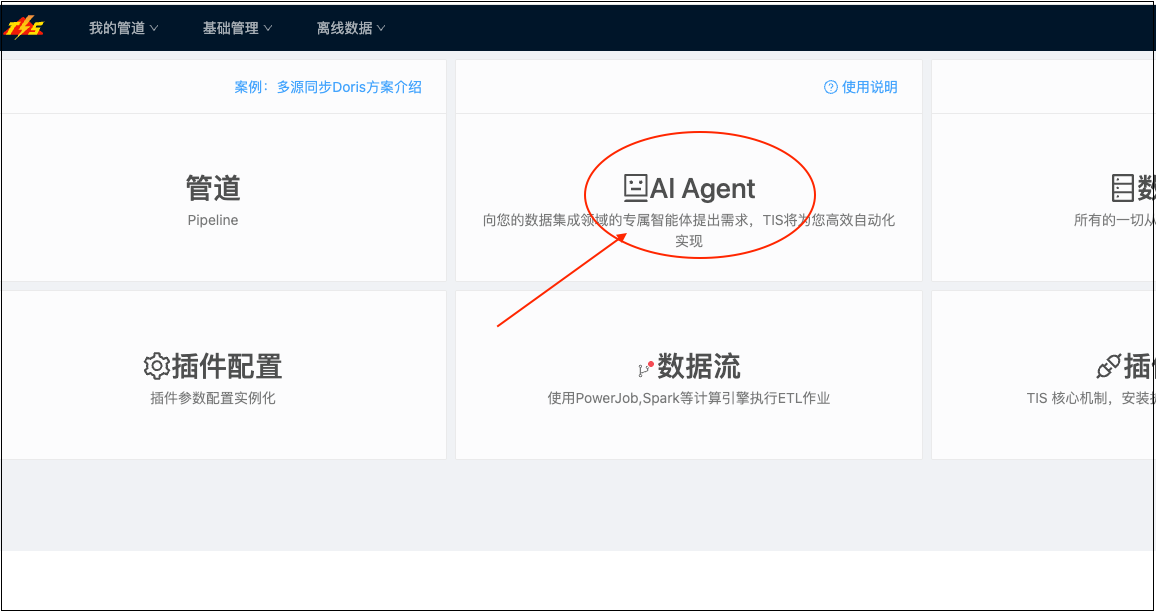
步骤1: 打开 AI Agent 对话界面
- 在 TIS 首页点击"创建数据管道"
- 选择"AI Agent 智能创建" (新功能标识 🆕)
- 进入聊天界面
AI Agent 智能创建入口
步骤2: 使用快捷模板 (可选)
点击底部的快捷模板按钮,快速填充常见场景:
- 📋 MySQL → Paimon 数据湖
- 📋 MySQL → Doris 实时数仓
- 📋 PostgreSQL → ClickHouse 分析
- 📋 Oracle → Hive 离线仓库
点击快捷模板按钮 快速编写符合自己需求的任务需求
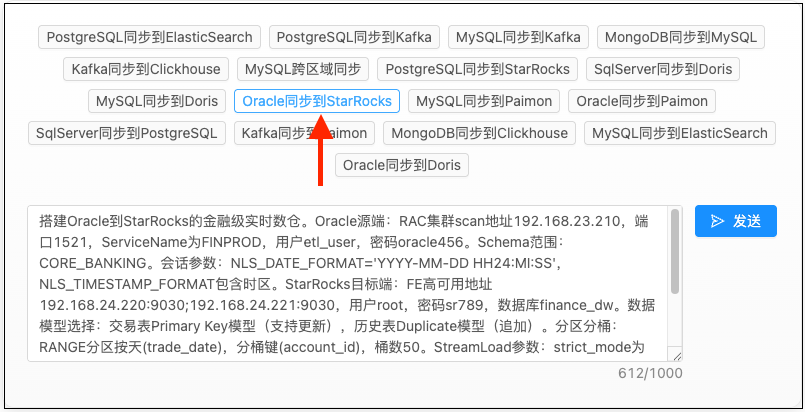
步骤3: 描述您的需求
在输入框中用自然语言描述需求,例如:
请创建一个从MySQL的shop_db库到Paimon的数据管道,
同步orders和customers两张表,需要实时增量同步
然后点击"发送"按钮 (或按 Ctrl+Enter)。
步骤4: 跟随 AI 引导完成配置
AI Agent 会自动执行以下步骤,您只需要在需要时填写配置:
插件安装 (自动) AI 会检测并安装缺失的插件,无需干预
MySQL 配置 (需要填写) 弹出配置对话框,填写数据库连接信息:
- 主机地址:
192.168.1.100 - 端口:
3306 - 用户名:
root - 密码:
******
点击"确认"提交
- 主机地址:
Paimon 配置 (需要填写) 填写 HDFS 和 Hive 连接信息,点击"确认"
选择表 (自动) AI 自动识别到 orders 和 customers,无需手动选择
启动同步 (自动) 批量同步和增量同步自动启动
步骤5: 完成!
看到"任务完成"消息后,您的数据管道已经成功创建并运行! 🎉
可以点击消息中的链接查看:
- 📊 批量同步进度
- 📈 增量同步日志
- ⚙️ 管道配置详情
交互技巧
✅ 推荐的描述方式
明确关键信息:
✅ 好: "从MySQL的test_db库同步orders表到Doris"
❌ 差: "同步数据库"
指定执行模式:
✅ 好: "需要实时增量同步"
✅ 好: "只做一次批量同步"
❌ 差: (不说明,AI会默认只做批量)
多表同步:
✅ 好: "同步orders、users、products三张表"
✅ 好: "同步所有以log_开头的表"
❌ 差: "同步一些表" (不明确)
💡 高级技巧
利用上下文记忆:
在同一会话中,后续创建管道可以复用之前提供的连接信息:
👤 第一次: 创建MySQL(192.168.1.100)到Paimon的管道...
🤖 [配置MySQL连接]
👤 第二次: 再创建一个从同一个MySQL到Doris的管道
🤖 检测到您之前已配置过该MySQL,是否复用? [是] [否]
分步确认:
如果不确定配置,可以要求 AI 先生成计划:
👤 请先给我一个从PostgreSQL到ClickHouse的方案,不要立即执行
🤖 好的,为您生成执行计划:
1. 安装 PostgreSQL Reader、ClickHouse Writer
2. 配置 PostgreSQL 连接 (需要提供主机、端口、用户名、密码)
3. 配置 ClickHouse 连接 (需要提供主机、端口、数据库)
4. 选择同步表 (您未指定,后续需要选择)
5. 批量同步 (默认)
是否继续执行? [确认] [取消]
功能边界:明确支持范围
✅ 当前支持
数据源 (Reader)
- 关系型数据库: MySQL、PostgreSQL、Oracle、SQL Server、DB2
- NoSQL: MongoDB、Cassandra、HBase
- 消息队列: Kafka
- 文件系统: HDFS、FTP、OSS
- 数据仓库: Hive、Doris (查询)
数据目标 (Writer)
- 数据湖: Paimon、Iceberg、Hudi
- 实时数仓: Doris、ClickHouse、StarRocks
- 搜索引擎: Elasticsearch、Solr
- 数仓: Hive、Snowflake
- 消息队列: Kafka
同步模式
- ✅ 批量同步: 全量历史数据同步
- ✅ 增量实时同步: 基于 CDC (Change Data Capture) 的实时同步
- ✅ 混合模式: 先批量后增量
操作类型
- ✅ 创建新管道
- ✅ 配置插件实例
- ✅ 选择同步表
- ✅ 启动/停止同步任务
- ✅ 查看执行日志
❌ 暂不支持
- ❌ 修改已有管道配置 (需要手动编辑)
- ❌ 复杂的字段映射和转换 (需要使用 Transformer 功能)
- ❌ 数据质量校验规则设置
- ❌ 自定义数据过滤条件
- ❌ 管道的删除操作 (需要手动删除)
替代方案: 对于暂不支持的功能,可以先用 AI Agent 创建基础管道,然后在管道详情页手动配置高级选项。
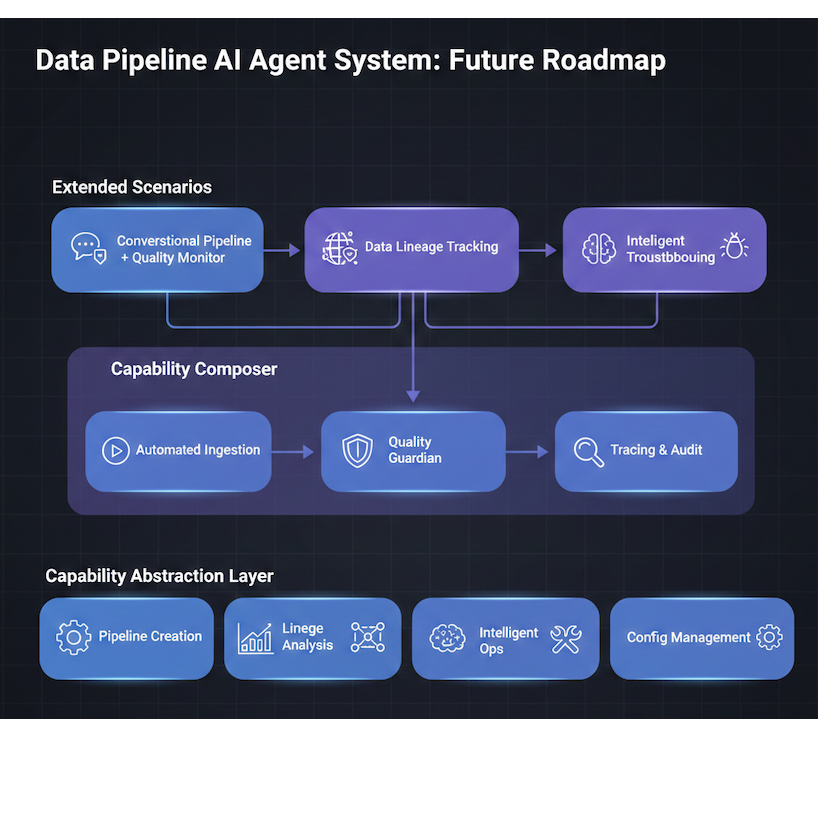
🚀 未来规划
基于 TIS 的能力抽象层设计,未来将支持:
1. 能力组合 (Capability Composition)
当前: AI Agent 只能创建数据管道 未来: 支持更多能力组合
👤 用户: 创建一个从MySQL到Doris的管道,并设置数据质量监控规则
🤖 AI: 我将为您完成:
1. 创建 MySQL → Doris 数据管道 ✅
2. 添加数据质量检查规则:
- 空值检测 (不超过5%)
- 重复值检测
- 数据分布监控
3. 设置告警通知 (钉钉/邮件)
2. 数据血缘分析
👤 用户: 分析orders表的数据血缘关系
🤖 AI: orders表的数据血缘:
📊 上游: MySQL shop_db.orders
📊 下游:
- Paimon datalake.orders (实时同步)
- Doris dw.fact_orders (每日ETL)
- ClickHouse analytics.order_events (实时推送)
3. 智能运维助手
👤 用户: 为什么我的MySQL到Doris管道同步延迟突然增加了?
🤖 AI: 我检测到以下异常:
1. Doris集群负载过高 (CPU 95%)
2. 源端MySQL有大量写入 (QPS从1000升至8000)
3. 网络带宽接近上限
建议措施:
1. 扩容Doris集群 (增加2个BE节点)
2. 调整同步并行度 (从4增至8)
3. 考虑错峰同步策略
未来规划架构图 - 展示能力抽象层、组合器、扩展场景
拥抱开源: 使用开源组件,回馈开源社区
站在巨人的肩膀上
TIS 本身是一款基于开源生态构建的开源产品。我们深知,开源策略对于 TIS 成为一款成功的数据集成软件具有重大意义。
TIS 融合了业界最优秀的开源组件:
- DataX:阿里巴巴开源的批量数据同步工具,支持数十种数据源
- Apache Flink:业界领先的流计算框架,提供强大的实时处理能力
- Flink CDC:实时数据捕获组件,支持多种数据库的增量监听
这些都是当下开源社区中人气旺盛、生产验证充分的组件,为 TIS 打下了坚实的技术基础。
有机融合,而非简单堆砌
TIS 并不是对这些组件的简单堆砌,而是通过模型驱动架构将它们有机地无缝衔接在一起。
Pipeline AI Agent 的诞生,正是这种融合的成果:
1. 模型驱动的架构基础
为了避免为每个前端业务编写重复的 CRUD 逻辑,TIS 采用了模型驱动的设计理念:
- 统一的元语义层:为每个业务模型定义强大的元数据语义
- 自动表单生成:前端组件可以根据元数据自动生成
- 一致的验证逻辑:参数校验、依赖关系检查统一处理
过去四年中,随着业务逻辑的不断迭代和持续重构,TIS 逐渐形成了一套语义一致、结构完整的元语义模型层。
2. 从元语义到 AI Prompt
有了这套元语义层,生成 AI Agent 的 Prompt 提示词就变得水到渠成:
// AI Agent 直接调用插件描述接口生成 Prompt
DescriptorsJSONForAIPromote.desc("com.qlangtech.tis.plugin.datax.DataxMySQLReader")
返回的 JSON 不仅包含插件参数,还包括:
- 字段类型、默认值、必填项
- 参数之间的依赖关系
- 插件的扩展点信息
- 嵌套插件的描述
这些丰富的元信息作为 Prompt 提交给大模型(DeepSeek / 通义千问),让 AI 能够真正"理解" TIS 的插件体系,从而准确地生成配置参数。
Pipeline AI Agent 核心代码架构
Pipeline AI Agent 的第一个版本已经完成,功能目前限于创建数据管道。后续版本我们将把 Agent 能力扩展到数据集成的各个领域(参见 未来规划)。
以下是 Pipeline AI Agent 功能相关的主要代码及说明:
1. 整体架构设计
采用 Plan-and-Execute Agent 模式,前后端分离架构:
com.qlangtech.tis.aiagent/
├── core/ # 核心控制
│ ├── TISPlanAndExecuteAgent # 主Agent控制器
│ ├── AgentContext # 执行上下文
│ └── TaskExecutor # 任务执行器
├── plan/ # 计划生成
│ ├── TaskPlan # 任务计划定义
│ ├── TaskStep # 任务步骤定义
│ └── PlanGenerator # 计划生成器
├── execute/ # 执行引擎
│ ├── StepExecutor # 步骤执行器接口
│ ├── PluginCreateExecutor # 插件创建执行器
│ └── PipelineExecutor # 管道执行器
├── llm/ # 大模型集成
│ ├── LLMProvider # 大模型接口抽象
│ ├── DeepSeekProvider # DeepSeek实现
│ └── QianWenProvider # 通义千问实现
├── template/ # 提示词模板
│ ├── PromptTemplate # 提示词模板
│ └── TaskTemplateRegistry # 任务模板注册表
└── controller/ # HTTP/SSE接口
└── ChatPipelineAction # SSE控制器
2. 核心组件说明
TISPlanAndExecuteAgent - 主控制器:
- 解析用户自然语言输入
- 生成结构化执行计划
- 协调任务执行流程
- 处理错误恢复
- 管理与用户的交互(询问缺失参数)
任务执行流程:
- 意图识别:接收用户输入 → 调用 LLM 解析意图
- 计划生成:匹配任务模板 → 生成执行计划
- 步骤执行:逐步执行任务 → 实时反馈进度(SSE)
- 参数补全:验证必需参数 → 询问缺失信息
- 插件创建:创建插件实例 → 配置数据管道
- 任务触发:触发批量/增量任务 → 监控执行状态
3. 插件实例创建流程
对于每个插件实例的创建:
// 1. 获取插件元数据描述
String pluginDesc = DescriptorsJSONForAIPromote.desc(
"com.qlangtech.tis.plugin.datax.DataxMySQLReader"
);
// 2. 将描述发送给LLM,结合用户输入解析参数
LLMResponse response = llmProvider.chat(
PromptTemplate.build(pluginDesc, userInput)
);
// 3. 验证必需字段,缺失则向用户询问
Map<String, Object> params = response.extractParams();
List<String> missingFields = validateRequiredFields(params);
if (!missingFields.isEmpty()) {
askUserForParams(missingFields); // 阻塞等待用户输入
}
// 4. 生成插件实例配置并创建
pluginSystem.createInstance(pluginType, params);
4. SSE 实时推送实现
基于 Server-Sent Events 实现服务端到客户端的实时消息推送:
public void doChat(Context context) {
String userInput = getString("input");
String sessionId = getString("sessionId");
// 设置SSE响应头
response.setContentType("text/event-stream");
response.setCharacterEncoding("UTF-8");
PrintWriter writer = response.getWriter();
// 创建Agent执行上下文
AgentContext ctx = new AgentContext(sessionId, writer);
// 执行Agent任务(异步推送进度)
TISPlanAndExecuteAgent agent = new TISPlanAndExecuteAgent(ctx);
agent.execute(userInput);
}
支持的SSE事件类型 (详见 SSERunnable.java):
AI_AGNET_MESSAGE:文本消息(支持打字机效果)AI_AGNET_PLUGIN:插件配置请求AI_AGNET_SELECT_TABS:表选择请求AI_AGNET_PLUGIN_INSTALL_STATUS:插件安装进度AI_AGNET_TOKEN:Token 消耗统计AI_AGNET_PROGRESS:任务进度AI_AGNET_ERROR:错误消息
回馈开源,与社区共同成长,这是 TIS 始终坚持的理念。
FAQ:常见问题解答
1. LLM 选择与配置
Q: 推荐使用哪个大模型?
A: 推荐 DeepSeek-V3,原因:
- ✅ 性价比极高 (0.14¥/百万tokens)
- ✅ 推理能力强,适合结构化任务
- ✅ 响应速度快
- ✅ 支持大上下文窗口 (64K)
对于企业用户,通义千问 也是不错的选择,阿里云生态集成更好。
Q: 如何获取 DeepSeek API Key?
A: 访问 https://platform.deepseek.com → 注册账号 → 进入"API Keys"页面 → 创建新密钥 → 复制到 TIS 配置中
Q: LLM调用失败怎么办?
A: 按以下步骤排查:
- 检查 API Key 是否正确
- 验证账户余额是否充足
- 测试网络连通性 (ping api.deepseek.com)
- 查看 TIS 日志 (/tis/logs/tis.log) 中的错误详情
2. 安全性考虑
Q: 我的数据库密码会被发送给 LLM 吗?
A: 不会。隐私保护机制:
- ✅ 用户填写的密码不会发送给 LLM
- ✅ 只有插件参数的 Schema 描述发送给 LLM
- ✅ LLM 只生成配置结构,不接触真实数据
- ✅ 密码在 TIS 服务端加密存储
3. 性能与成本
Q: 创建一个管道大概消耗多少 Token?
A: 典型场景:
- 简单管道 (MySQL → Paimon): 15000-25000 tokens (约 ¥0.003)
- 复杂管道 (多表、嵌套插件): 30000-50000 tokens (约 ¥0.007)
- 错误重试、多轮交互: 50000-100000 tokens (约 ¥0.014)
Q: 如何减少 Token 消耗?
A:
- 精简需求描述 (见"Token优化建议"章节)
- 复用会话上下文
- 提前准备配置信息,减少重试
- 选择 DeepSeek 等低成本模型
Q: AI Agent 创建的管道性能如何?
A: 与手动创建的管道完全一致,因为:
- ✅ 底层使用相同的 DataX 和 Flink 引擎
- ✅ 生成的配置经过验证和优化
- ✅ 只是改变了创建方式,不改变运行时逻辑
4. 功能限制
Q: 可以修改已创建的管道吗?
A: 目前 AI Agent 暂不支持修改已有管道,但您可以:
- 在管道详情页手动编辑配置
- 或者删除管道后重新用 AI Agent 创建
Q: 支持自定义字段映射吗?
A: 当前版本 AI Agent 使用默认的同名映射,如需自定义映射:
- 先用 AI Agent 创建基础管道
- 在管道详情页 → "字段映射"Tab 手动调整
- 未来版本将支持在对话中指定映射规则
Q: 能否设置数据过滤条件?
A: 暂不支持在 AI Agent 中设置过滤条件,可以:
- 在管道详情页 → Reader 配置 → 添加 WHERE 条件
- 或使用 Transformer 功能进行数据过滤
5. 其他问题
Q: 如何查看历史会话?
A: 左侧会话列表展示所有历史会话,点击即可切换。会话会持久化保存,重新登录后仍可查看。
Q: 可以分享会话给同事吗?
A: 当前版本会话是用户私有的,暂不支持分享。未来版本将支持会话导出和导入功能。
Q: AI Agent 支持哪些语言?
A: 目前主要支持中文,英文也可以使用但效果可能不如中文。未来将优化多语言支持。
总结:开启数据集成新时代
TIS Pipeline AI Agent 的推出,标志着数据集成工作从"配置时代"进入"对话时代"。
核心价值
- ⏱️ 提升效率: 创建管道时间从 30 分钟缩短到 3 分钟
- 🎯 降低门槛: 无需深入学习插件配置,自然语言即可上手
- 🧠 智能辅助: LLM 自动推断参数,减少人工填写
- 🚀 技术领先: 国内首个大数据原生 AI Agent,Plan-and-Execute 架构
适用人群
- 📊 数据分析师: 快速搭建数据管道,专注数据分析
- 🔧 数据工程师: 提升开发效率,避免重复配置
- 🏢 企业用户: 降低人员培训成本,加速数据项目落地
- 🎓 学习者: 通过对话式交互学习数据集成知识
立即开始
- 升级到 TIS v5.0
- 配置 LLM 提供者 (推荐 通义千问QWen)
- 点击"AI Agent 智能创建"
- 用自然语言描述需求,开始体验! 🎉
让数据管道听懂人话,让数据集成更简单!