利用TIS实现T+1离线分析
功能说明
通过数据流管理可以方便实现离线批量数据分析,借助传统Map/Reduce工具(Aliyun ODPS,Hive,Spark等)将抽取得到的数据快速进行离线数据分析,得到所需要的结果。
虽然,现在业界实时数仓构建非常火热,但是基于传统MapReduce工具为代表的离线分析工具依然不可或缺,在很多业务场景中发挥着重要作用。他的特点是架构简单、可靠,可以执行复杂的T+1报表分析业务。
另外,在实时数仓建设领域,可以有效弥补实时数仓的技术短板。离线分析结果可以作为下游实时数仓(Doris,StarRocks,ElasticSearch)的数据源,例如StarRocks作为一款非常优秀的OLAP引擎,内部有强大的多表Join查询能力,如想进一步提高OLAP数据分析能力,可以利用TIS数据流管理模块在引擎外部就构建多表关联物化视图
,将物化视图作为数据源导入到StarRocks中,这样免去了StarRocks引擎内部执行多表Join操作。
一套完整的离线分析引擎需要有三部分,
离线分析引擎目前,TIS数据流管理支持三种离线分析引擎,- Spark
- Hive
- AliyunODPS
任务调度引擎
因为一个大离线分析任务往往有N个子任务工程,且子任务与子任务之间是有上下游依赖关系(每个子任务的触发需要依赖它的上游任务完成),这些子任务之间构成了DAG图,业界有专门工具 , 比较成熟的调度工具有 Apache dolphinscheduler , Apache Airflow,PowerJob
数据采集工具
数据采集流程是,离线数据分析的前置步骤,现在业界流行的工具有,Apache SeaTunnel,阿里巴巴开源工具DataX,Airbyte
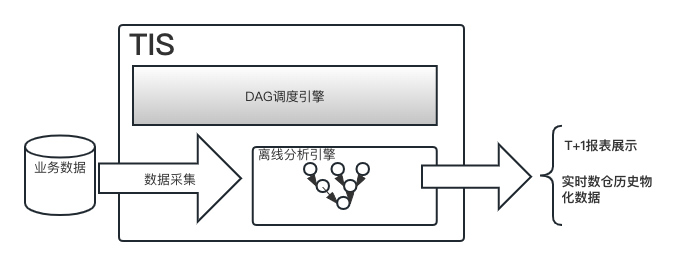
TIS 系统内部集成了以上三部分,选取业界最优秀的工具组件无缝集成,为用户提供一站式、开箱即用的离线分析平台工具。
使用说明
案例介绍
假设需要基于关系型数据库来执行离线分析,本案例提供了一个Demo数据库,有关简单员工(Employees)CRM管理系统的数据库,库中各表ER关系如下:
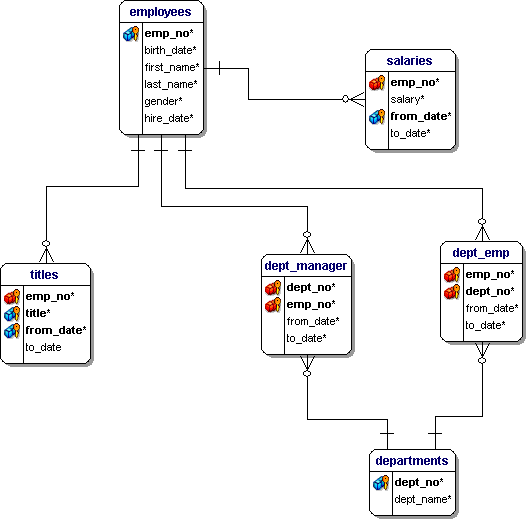
基于以上表需要完成一个离线分析,统计研发部(Development)收入前5的员工名单,实现此需求需要执行以下SQL:
SELECT e.first_name, e.last_name, e.gender,dpt.dept_name, s.salary
, de.from_date as de_from_date ,de.to_date as de_to_date ,
s.from_date as s_from_date, s.to_date as s_to_date
FROM employees e
INNER JOIN salaries s ON(e.emp_no = s.emp_no )
INNER JOIN dept_emp de ON(e.emp_no = de.emp_no)
INNER JOIN departments dpt on(de.dept_no = dpt.dept_no)
WHERE dpt.dept_name = 'Development'
AND de.from_date >= '1990-01-22' AND de.to_date <= '1991-01-22'
AND s.from_date >= '1990-01-22' AND s.to_date <= '1991-01-22'
ORDER BY s.salary DESC
LIMIT 5
执行结果为:
| first_name | last_name | gender | dept_name | salary | de_from_date | de_to_date | s_from_date | s_to_date |
|---|---|---|---|---|---|---|---|---|
| Georgi | Denos | F | Development | 88947 | 1990-04-18 | 1990-05-04 | 1990-04-18 | 1990-05-04 |
| Sanjoy | Plotkin | F | Development | 70931 | 1990-04-11 | 1990-05-27 | 1990-03-26 | 1990-05-27 |
| Keiichiro | Kavraki | M | Development | 65989 | 1990-02-26 | 1990-04-11 | 1990-02-26 | 1990-04-11 |
| Adas | Luef | F | Development | 65061 | 1990-07-09 | 1990-12-22 | 1990-07-09 | 1990-12-22 |
| Kenroku | Varley | M | Development | 64622 | 1990-04-22 | 1991-01-20 | 1990-10-26 | 1991-01-20 |
构建离线分析:
优化方案
倘若最终需会将数据同步到实时数仓Doris中作为OLAP查询引擎,以上,查询条件(dept_name,from_date,to_date)会根据不同的业务需求而变,所以我们需要在离线分析引擎中构建一张业务中间表emp_dpt_salaries
CREATE TABLE `emp_dpt_salaries`
AS
SELECT e.first_name, e.last_name, e.gender,dpt.dept_name, s.salary
, de.from_date as de_from_date ,de.to_date as de_to_date ,
s.from_date as s_from_date, s.to_date as s_to_date
FROM employees e
INNER JOIN salaries s ON(e.emp_no = s.emp_no )
INNER JOIN dept_emp de ON(e.emp_no = de.emp_no)
INNER JOIN departments dpt on(de.dept_no = dpt.dept_no)
最终,会将 emp_dpt_salaries 表导入到Doris中,在Doris库中直接使用以下SQL进行业务查询:
SELECT e.first_name, e.last_name, e.gender,e.dept_name, e.salary
FROM emp_dpt_salaries e
WHERE e.dept_name = 'Development'
AND e.de_from_date >= '1990-01-22' AND e.de_to_date <= '1991-01-22'
AND e.s_from_date >= '1990-01-22' AND e.s_to_date <= '1991-01-22'
ORDER BY e.salary DESC
LIMIT 5
试想,这样的查询性能是不是会好到炸裂
TIS中操作流程
| 说明 | 图示 |
|---|---|
| 初始化Employees数据库,并且在TIS中注册employees数据源,以备后续流程中使用 |  |
打开链接/offline/wf,点击右侧图示中创建按钮,进入数据流定义页面 |  |
| 设置离线分析实例名称 |  |
| 设置离线引擎类型,本例中选择Aliyun ODPS 作为分析引擎(需要先到Aliyun上申请ODPS服务) |  |
| 设置ODPS引擎相关配置参数 | 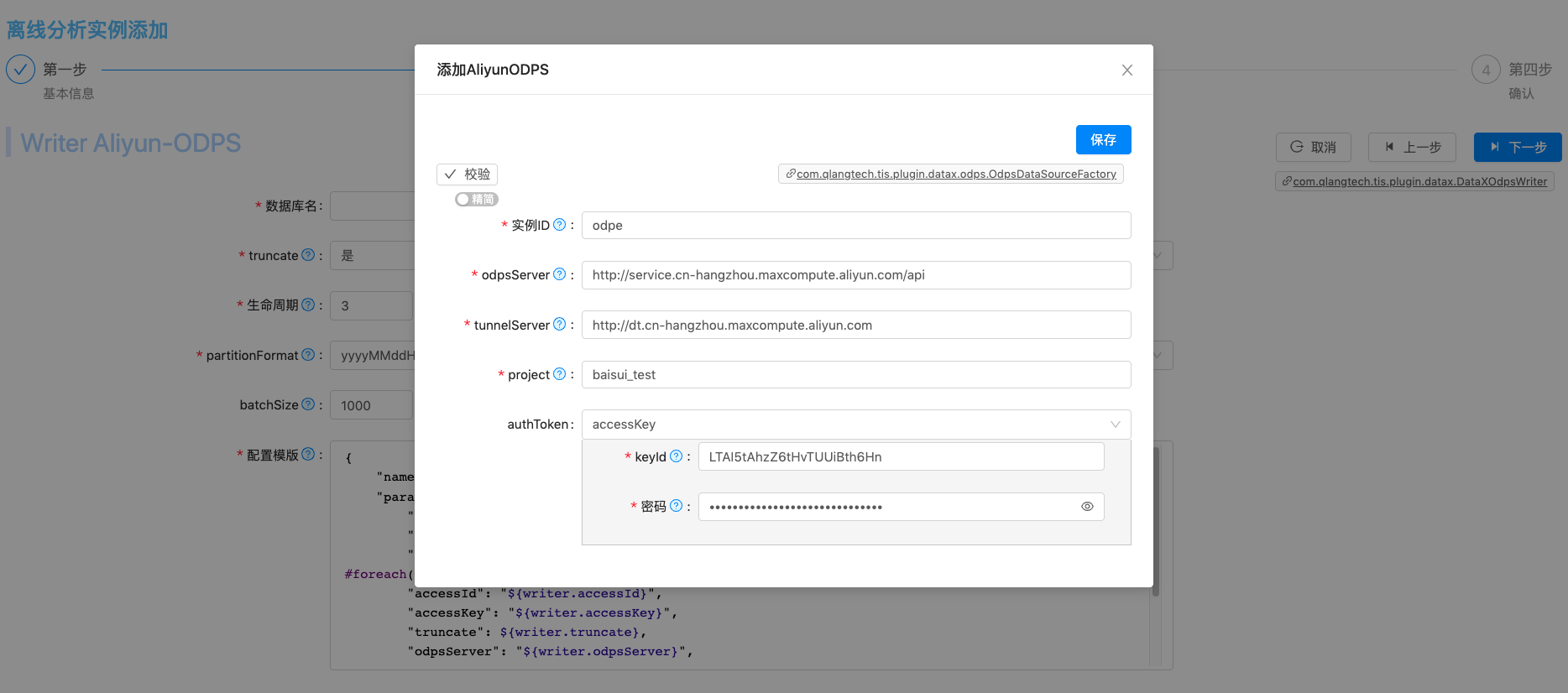 |
1. 点击左侧控件栏中的数据库表到托盘中 2.自动打开数据表选择输入框 3. 数据库表下拉选择框中选择需要导入的表(employees,salaries,dept_emp,departments),需要在 前一步 中已经定义完成 |  |
1.点击左侧控件栏中的JOIN到托盘中 2.设置 名称JOIN节点名称,选择依赖节点,在SQL中填写数据处理脚本 3.点击保存 |  |
点击保存按钮,对新添加的数据流规则进行保存 |  |
| 保存成功,会跳出确认对话框,询问是否需要定义表ER关系 ER关系规则在增量执行流程中使用,如果后期不需要开启增量同步管道,则可以跳过这一步 | 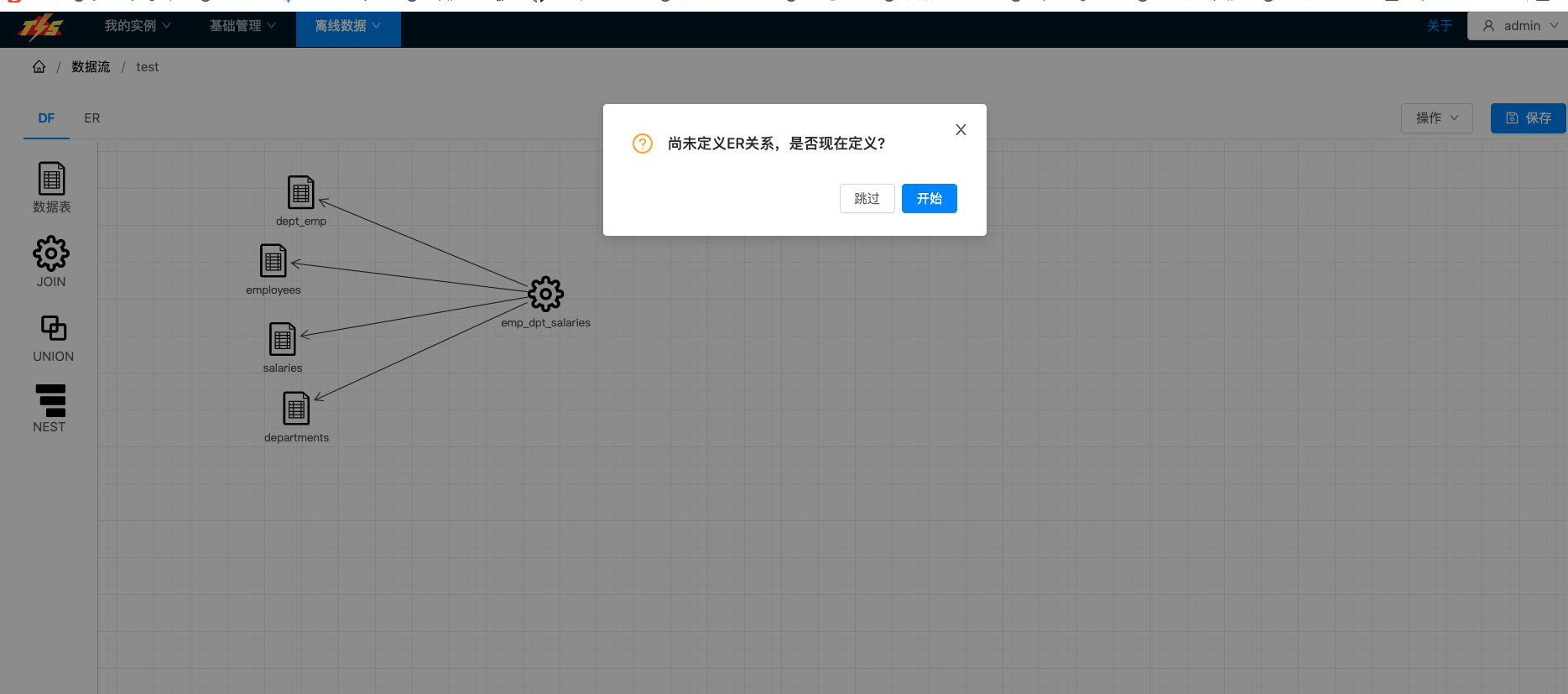 |
| 开始编辑表实体关系 1.设置是否是主索引表 注:一个数据流中的多个表实体只能有一个表设置为主索引表 2.当设置为主索引表之后需要 添加主键列,主键列的所用是增量执行过程中到数据库中反查主表数据时用的,另外还要设置分区键,这是在反查数据表时使用的路由键 3.设置是否开启 监听增量变更,如开启则会在增量处理流程中会将表中的变更同步到Solr引擎中 4. 点击 保存按钮完成实体定义 | 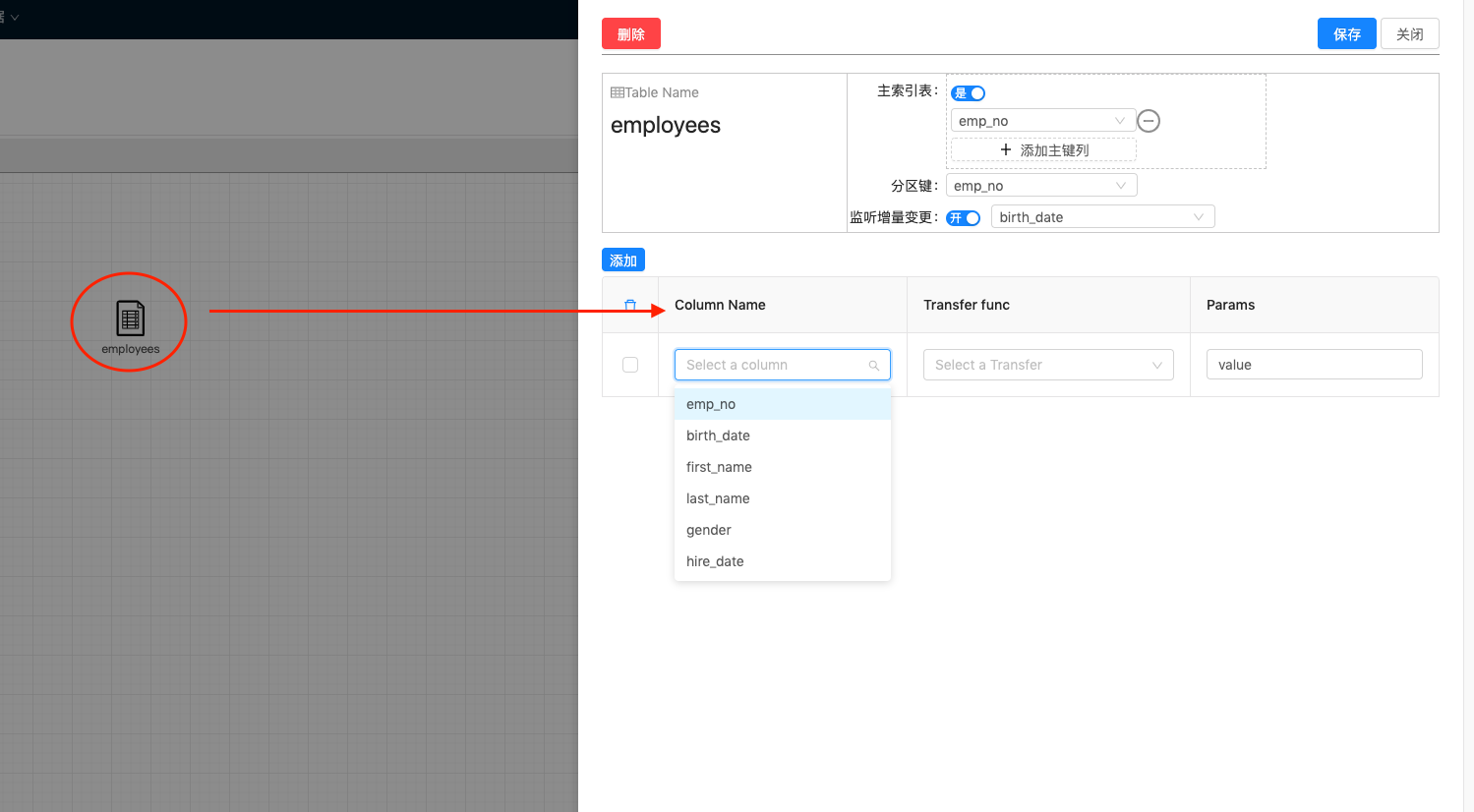 |
回到主页面,点击右上方保存按钮对ER关系进行保存 千万别忘保存哦!!! |  |
执行数据流
| 在正式开始执行数据分析之前,为保证编写的脚本正确,可以先用DryRun模式运行已经完成的dataflow |  |
以DryRun模式运行成功之后,回到列表页面/offline/wf,点击右图所示构建按钮,开始执行数据流构建 | 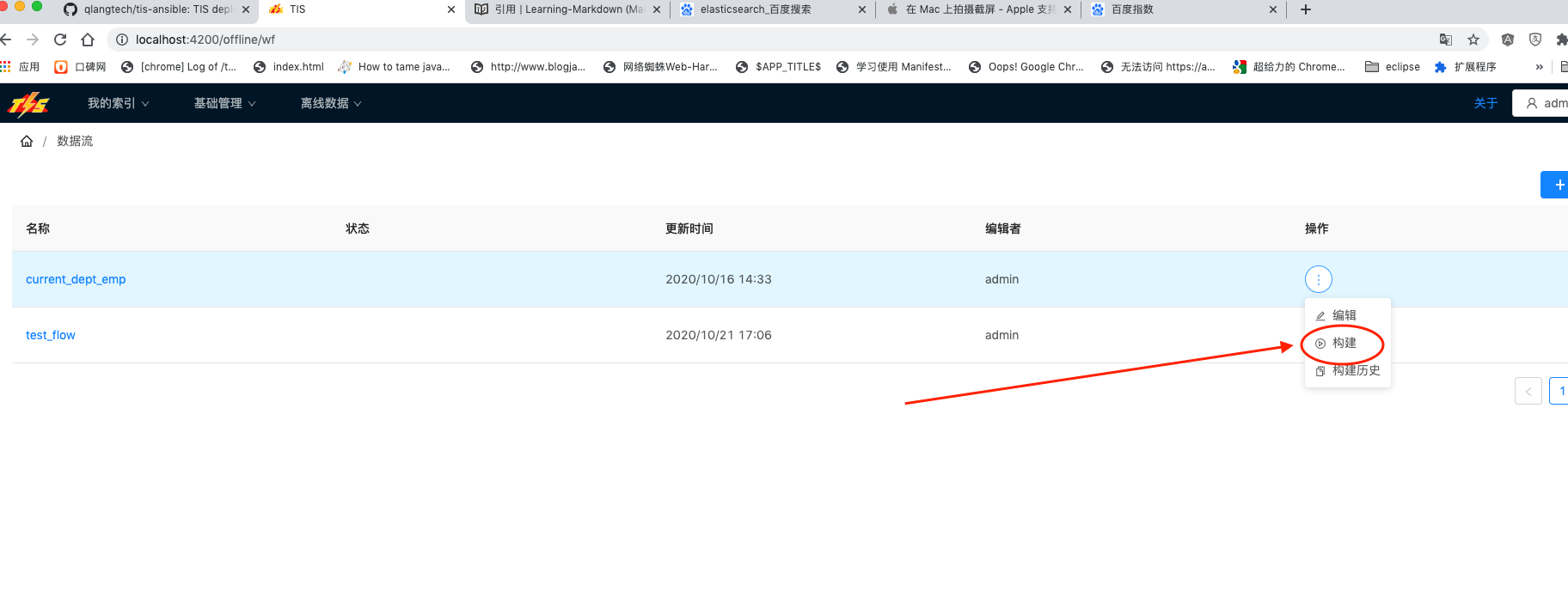 |
触发构建流程成功,就可以跳转到 /offline/wf/build_history/1/6 数据流构建执行状态查看页面,在该页面中可以查看构建流程中各种状态信息 如全流程可顺利执行完成说明数据流定义没有错误 |  |