多源同步Doris方案介绍
本文导读
Apache Doris 是新一代MPP架构的高性能、实时的分析型数据库。作为一款可靠的OLAP引擎产品,企业内部会将OLTP数据库与其进行整合,通过从OLTP数据库(例如:MySQL,SqlServer)同步数据到Doris的方式,为线上业务团队提供业务支持,例如:用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
随着这种模式越来越流行,企业内部需要构建大量端到端的数据通道,有的是批量同步构建T+1报表用,有的需要实时同步构建,有的还需要在同步过程对数据作一些处理,比如:数据脱敏,格式变化等等。这些工作,耗费了数据开发工程师大量时间。TIS为了将数据开发工程师从琐碎、重复、繁重的数据通道构建工作中解放出来,在大数据端到端的数据整合方面进行了有益的探索及尝试。
本文就据源中最常用到的,MySQL同步Doris作为案例,向大家讲解TIS原理,功能特性、优势。希望通过此文大家能够对TIS有一个初步的了解。
TIS 介绍
TIS 实现了多数据源端到端的数据同步,使用批量和实时增量的方式。TIS经过多年精心打造,专注用户侧使用体验,在操作界面化、流程化上下了不少功夫。
TIS有别于传统大数据ETL工具,它借鉴了DataOps、DataPipeline理念,对大数据ETL各个执行流程建模,将传统的ETL工具执行以黑屏化工具包的方式(json+命令行执行)升级到了白屏化2.0的产品化方式(系统借助底层的MetaData自动生成脚本,用户只需轻点鼠标,借助系统给出的提示快速录入配置),从而大大提高了工作效率。
所谓白屏化1.0,是系统虽然也是基于UI界面的,但是交互方式基本上是给一个大大的TextArea,里面填写的Json、XML、Yaml需要用户自己发挥了,这对用户来说执行效率还是太低了,我们暂且称这交互方式的系统为DevOps系统,TIS已经跨越到了白屏化2.0的DataOps系统了。
正因以上这些特性,TIS的使用者不仅只限于大数据技术开发工程师,而且,对数据分析师也非常友好,只需专注业务流程而不需要过多关注底层技术细节,就能轻松玩转大数据。
TIS 在构建过程中参考了Jenkins 的架构设计,在以下几个方面做尝试:
插件化封装
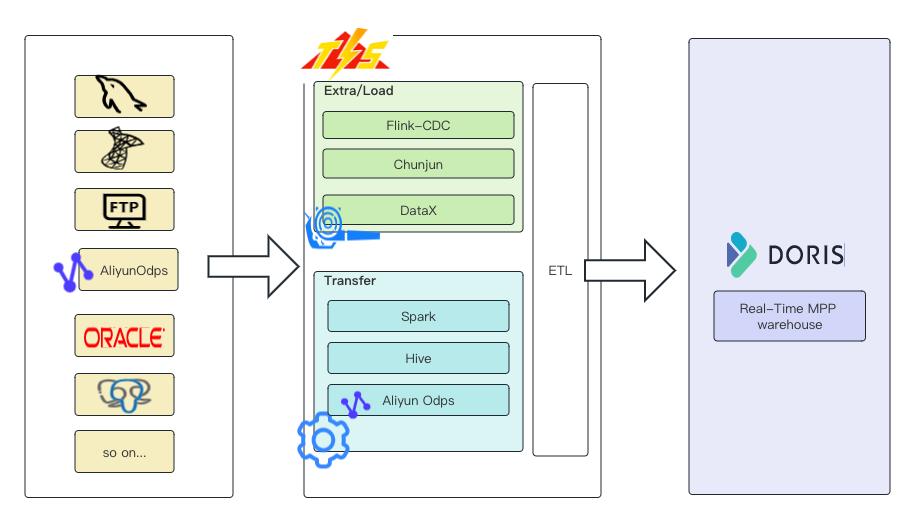
TIS 参考了Jenkins 实现方式,通过对业务模型建模,按照 OCP 开发准则,在TIS 概念抽象层定义了一套标准的面向大数据, ,并且基于这些扩展点进行扩展,例如,针对目标端 Doris,TIS 现已基于数据源扩展点DataSourceFactory 进行扩展,实现了多个业务扩展,如下图:
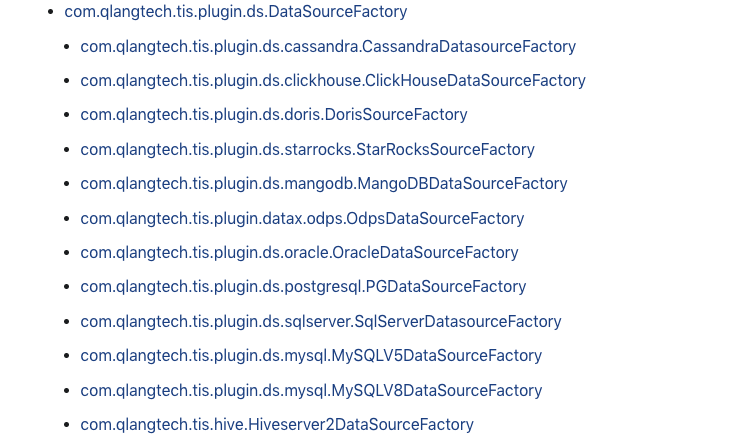
在构建数据通道过程中,用户可以选择任何一种数据类型作为Doris的数据源。使用方式也很简单,在TIS界面有一个类似安卓、苹果AppStore的的插件池列表,根据列表中的插件功能介绍,选择安装即可生效并使用。
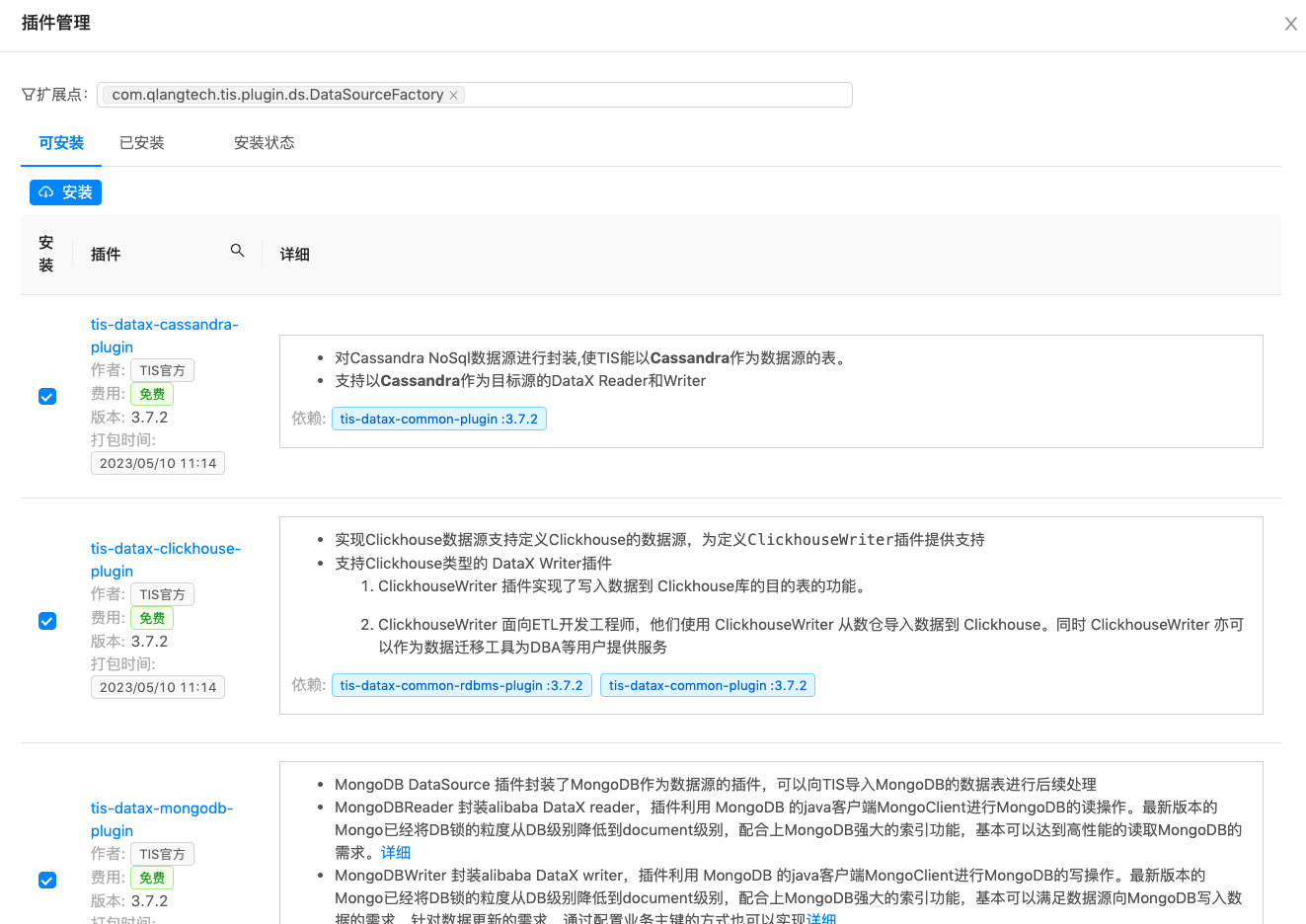
界面化处理
TIS 在内部构件了一套强大的 UI-DSL系统,利用 Java 领域模型在运行时动态渲染生成所有前端 html javascript 脚本,好处是:TIS 使用体验统一 ,另外对于 TIS 的开源贡献者来说友好,开发者一般都是后端开发者不擅长前端开发,而 TIS 只需要用户变现基于 Java 的领域模型即可。
使用更简单
TIS 屏蔽底层组件的配置复杂度,使用大量开源社区的组件,例如:Flink-CDC,Chunjun,DataX,Doris-connecto,Elastic-Connector,kafka-connector 等,这些开源组件每个单独都是可以使用的,基本都是通过代码,Json、XML配置的方式来驱动执行的,因此,需要重复配置大量参数。
TIS通过元数据反射,采用大量自动化生成配置的方式,加上,预设参数免去了用户手动配置参数,例如:Doris Stream load 数据导入流程需要选择,传输文本以 CSV 或者 JSON 方式传输,TIS 预设 JSON 作为文本传输格式,因为在用户视角来看,使用何种传输格式他并不关心,而关心的是,是否可以顺畅地将数据源中的数据传输到 Doris 数据库中,TIS 在实施过程中发现,JSON 作为传输文本最可靠,所以就使用 JSON 格式作为传输文本。
TIS 充当了厨师的角色,有各种新鲜的食材,利用厨师厨艺焕发出食材的美味,各位食客只需坐等厨师烹饪完毕,享用美味即可。
案例演示
以上说了这么特性还是不够形象,接下来我们通过MySQL同步Doris的具体案例向大家进一步说明
STEP.1 安装TIS
安装部署相关具体步骤请查看,下面给出项目安装相关演示视频:
STEP.2 准备数据
还需要准备好源端数据库 MySQL(版本为5.7.1)和目标端 Doris 库
Doris库准备
本案例使用 Doris 最新稳定版本 1.2.4.1 Doris部署说明 作测试。
MySQL库准备
MySQL数据库中需要初始化数据表,本案例可使用的是开源MySQL基准测试库 按照介绍自行初始化数据库。
STEP.3 构建批量数据管道
所谓批量数据管道就是原中的历史记录通过TIS底层依赖的DataX组件一次性全部倒入,批量同步的优点是,架构实现简单,吞吐量大,具体操作步骤可观看以下演示视频 以上视频中已经实现了针对Doris的添加、更新、删除同步操作,尤其是更新和删除操作Doris有自己独特的实现方式:
删除操作
借助Doris Stream Load方式[1] 的merge_type为Merge的操作来对需要删除的记录进行标记删除
更新操作
借助 Doris 的 Sequnce 机制[2],在 Source 端乱序到达的情况下,保证 Doris库中的记录不会有脏写的情况发生。在设置表信息,需要设置表 Sequence 列属性,在表属性页面提供下拉列表,其中的值为该表中所有整型数字类型和日期类型(date、datetime)类型的字段,供用户选择,当设定某列为 Sequence 列,TIS 自动生成的 DDL 语句,会自动在 PROPERTIES 中添加以下两个属性:
CREATE TABLE `test` (
id BIGINT
)
UNIQUE KEY(`totalpay_id`)
PROPERTIES("...
, "function_column.sequence_col" = 'last_ver'
, "function_column.sequence_type"='BIGINT' )Doris 内部会在新建表中添加一个隐藏列:DORIS_SEQUENCE_COL, 每次更新时,会在stream load的提交请求的http head中添加一个字段:
http.setHeader(
"function_column.sequence_col", "last_ver");Doris 服务端会将记录的某一列值与之比较,如果大于等于,则会更新该记录并且将DORIS_SEQUENCE_COL的最新值置为,否则直接丢弃掉。
以上的设置都是 TIS 内部自动实现的,毋需用户关心,用户只需保证选定的 sequence 列每次记录更新时,该列的值严格自增,不然就会发生 Doris 记录脏写的问题。
STEP.4 构建增量数据管道
生产环境中如有实时 OLAP 查询的需求,可以在前一批量同步的基础之上继续创建增量同步通道实例,来实现 MySQL 到 Doris 的毫秒级近实时同步效果,详细请查看以下视频。
STEP.5 执行结果确认
TIS 3.7 版本开始,为了方便用户做数据验证操作,已经将 Apache Zeppelin 整合进了 TIS,以下视频演示了如何通过 TIS Notebook 来验证 MySQL 同步 Doris 的增量执行逻辑是否正确
功能点优化
市场上做数据集成的工具不少,功能边界都差不多,能在用户心智中形成差异化就只能是产品细节,因此TIS的开发者非常关注用户在数据集成时的使用体验。时刻关注用户在使用 过程中碰到的问题,并且在TIS中提出解决方案。
利用Flink侧流减轻数据源压力
经常会看见用户在Flink-CDC社区用户群中咨询以下问题:
只要利用Flink的Side Outputs 机制,统一启动一个Flink-CDC 的MySQL Source Connector,接收到 MySQL的变更数据之后,根据表名通过Side Outputs来作分流,由原来每个表需要分别启动一个MySQL监听客户端,变成多个表监听,只需要启动一个客户端就行,这样就大大减轻了对MySQL的压力。
这个优化已经在TIS中天然集成了,所以在执行MySQL整库同步Doris时不需要担心启动多个MySQL库连接引发的性能问题了。
生态共荣
另外一个反复会在Flink-CDC中提出的问题是
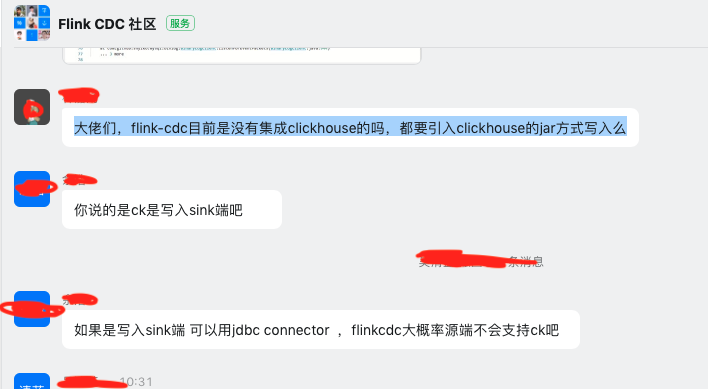
为了最大限度地方便用户操作,TIS整合了目前行业中实现写目标端最好的框架Chunjun,因为Chunjun和Flink-CDC都是在 Flink生态中的,将二者整合在一起难度并不大。经过适配,可以在TIS中实现用Flink-CDC实现的Source端于Chunjun 实现的Sink实现数据互通。
优雅实现分库分表
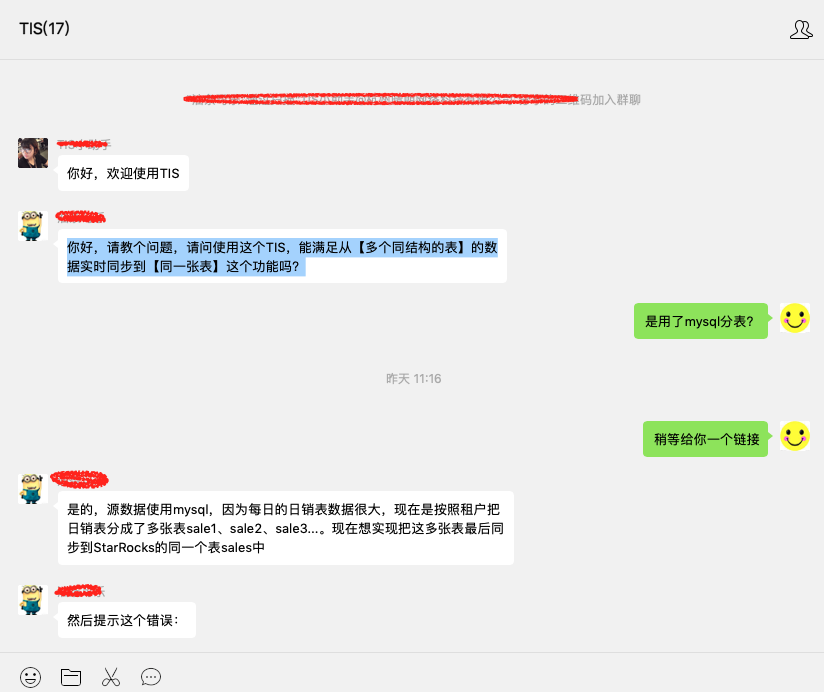
面对大数据场景,应用会在数据库之上做分库分表的存储策略优化,在做数据集成时,需要将分库分表作为一个统一的逻辑表同步到下游的Doris或者ElasticSearch引擎中,TIS中对这种使用场景给出了优雅的解决方案。
只需要在数据源表单中开启表分区策略即可将分库分表的多张物理表作为一张逻辑表来处理,用户不需要关心后续流程执行,详细请查看
后期规划
通过使用 TIS 之后,使原有的构建数据通道的效率有了较大的提升。希望本文阅读者能够举一反三,利用 TIS 功能丰富的插件实现更多的数据同步案例。 接下来,TIS 并不会止步于此,还会在以下几方面作出努力:
拥抱 CloudNative
随着云原生时代到来,云上 PAAS 产品的低成本、快捷、稳定可靠是几大优势,相信未来会有越来越多的企业拥抱云原生。 图片 TIS 在这方面也有自己的计划,接下来会将 TIS 全面支持 Docker K8S 部署,可以很方便地部署在各大云厂商的 K8S 环境中,与云厂商提供的 IAAS 层产品打通。支持用户跨云厂商部署,TIS 作为各云厂商 PAAS 产品之上的一个 Facade(门面)适配云厂商底层的 PAAS 层产品,让用户在跨云使用 ETL 工具有一致的用户体验。
丰富插件生态
目前 TIS 支持 MySQL、SqlServer、Oracle 等业界常用的关系数据库作为 Doris 的源端数据类型,后期还要扩展更多的数据类型,例如:TDEngine,AWS S3 及 S3 Glue 等等,让更多的数据类型的数据源能够汇聚到 Doris,发挥 Doris 的威力。
另外,TIS 还要开发一系列的支持生态开发者的工具,让开发者更顺畅地利用 TIS 来扩展 TIS 的 Extned Point。
扩展功能边界
读者已经发现,以上介绍的案例还只是实现了端到端的数据同步,只是实现了 ETL的 Extra(数据抽取)和Load(数据加载)两个环节,TIS 新测试版本中已经引入了一个 Transfer(数据处理)模块,用户在使用过程中,可以很方便地切换数据处理引擎(目前支持 Hive,Spark和 AliyunODPS )[3],利用 TIS 内置的调度引擎完成离线 DAG 任务调度,这样 Doris 的用户可以很方便地在 TIS 中构建一个离线分析计算宽表,待计算完成,再将计算结果导入到 Doris 集群中,可以进一步提升 OLAP 查询分析性能。
结语
TIS 最终的目标是打造一款人人都会用的数据集成产品,让用户可以在 TIS 之上,一站式、开箱即用地打造属于自己的ETL数据仓库。