MariaDB
数据源配置
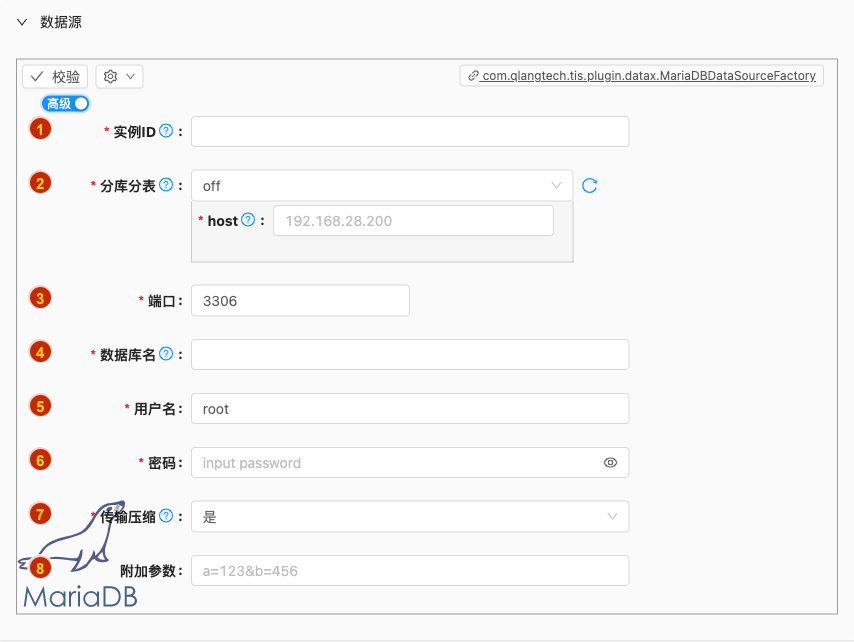
- 配置项说明:
实例ID
- 类型: 单行文本
- 必须: 是
- 默认值: 无
- 说明: 数据源实例名称,请起一个有意义且唯一的名称
分库分表
类型: 单行文本
必须: 是
默认值: off
说明:
如数据库中采用分表存放,可以开启此选项,默认为:
off(不启用)on: 分表策略支持海量数据存放,每张表的数据结构需要保证相同,且有规则的后缀作为物理表的分区规则,逻辑层面视为同一张表。 如逻辑表order对应的物理分表为:order_01,order_02,order_03,order_04
端口
- 类型: 整型数字
- 必须: 是
- 默认值: 3306
- 说明: 无
数据库名
- 类型: 单行文本
- 必须: 是
- 默认值: 无
- 说明: 数据库名,创建JDBC实例时用
用户名
- 类型: 单行文本
- 必须: 是
- 默认值: root
- 说明: 无
密码
- 类型: 密码
- 必须: 是
- 默认值: 无
- 说明: 无
传输压缩
类型: 单选
必须: 是
默认值: true
说明:
与服务端通信时采用zlib进行压缩,效果请参考https://blog.csdn.net/Shadow_Light/article/details/100749537
附加参数
- 类型: 单行文本
- 必须: 否
- 默认值: 无
- 说明: 无
批量读
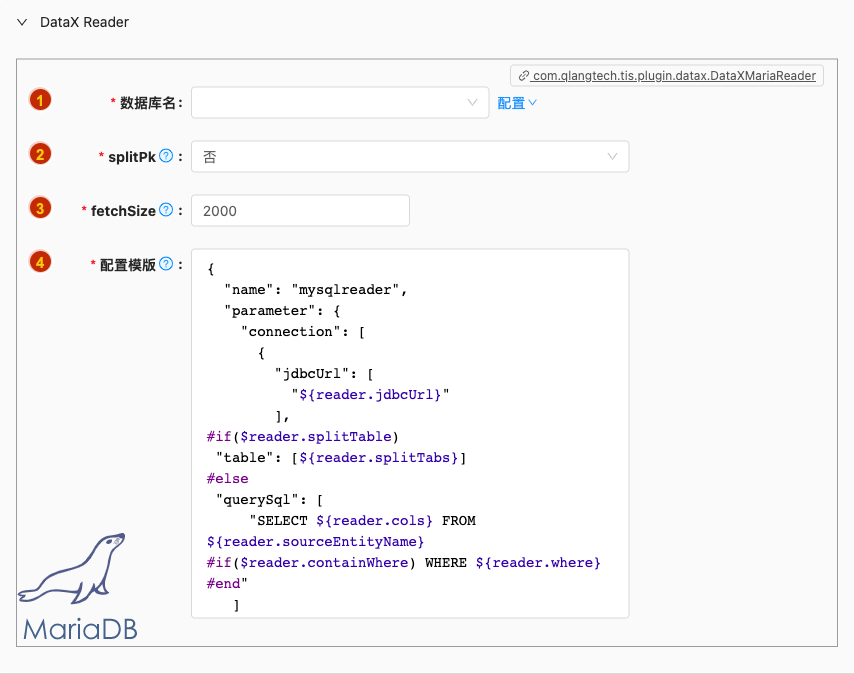
- 配置项说明:
数据库名
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 无
splitPk
- 类型: 单选
- 必须: 是
- 默认值: false
- 说明: 进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。 推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。 目前splitPk仅支持整形数据切分,不支持浮点、字符串、日期等其他类型。如果用户指定其他非支持类型,MysqlReader将报错! 如果splitPk不填写,包括不提供splitPk或者splitPk值为空,DataX视作使用单通道同步该表数据。
fetchSize
- 类型: 整型数字
- 必须: 是
- 默认值: 2000
- 说明: 执行数据批量导出时单次从数据库中提取记录条数,可以有效减少网络IO次数,提升导出效率。切忌不能设置太大以免OOM发生
配置模版
- 类型: 富文本
- 必须: 是
- 默认值: com.qlangtech.tis.plugin.datax.DataxMySQLReader.getDftTemplate()
- 说明: 无特殊情况请不要修改模版内容,避免不必要的错误
批量写
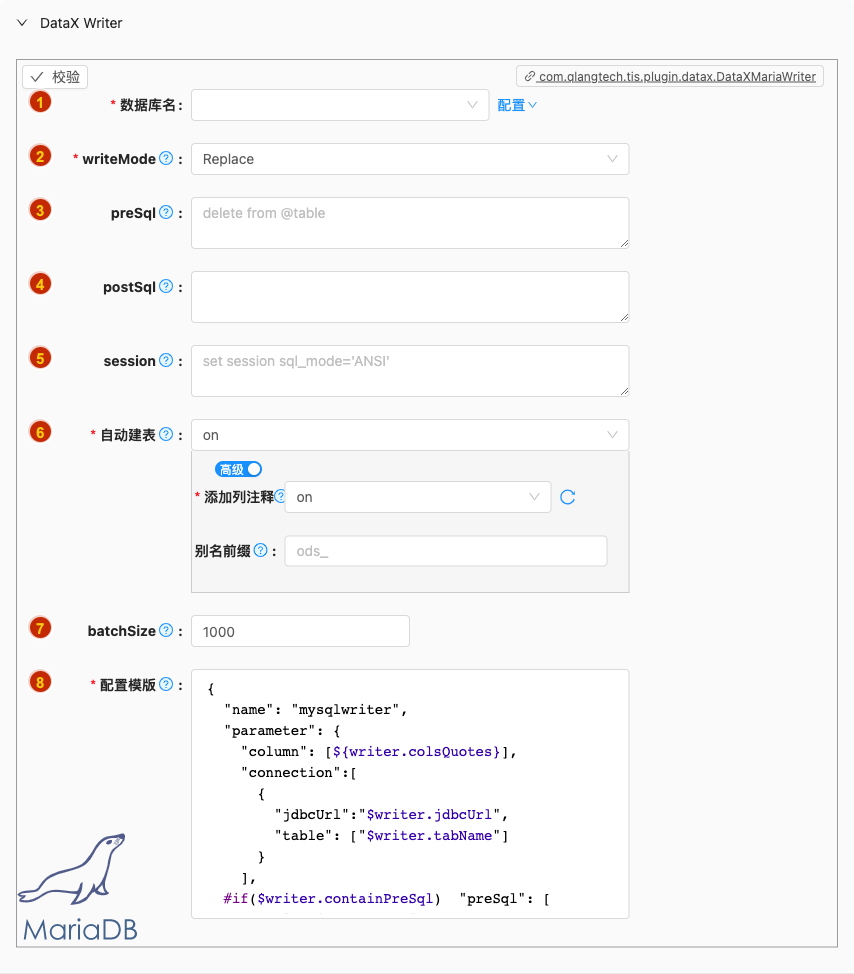
- 配置项说明:
数据库名
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 无
writeMode
类型: 单选
必须: 是
默认值: replace
说明:
控制写入数据到目标表采用
insert into或者replace into或者ON DUPLICATE KEY UPDATE语句
preSql
类型: 富文本
必须: 否
默认值: 无
说明:
描述:写入数据到目的表前,会先执行这里的标准语句。如果 Sql 中有你需要操作到的表名称,请使用
@table表示,这样在实际执行 Sql 语句时,会对变量按照实际表名称进行替换。比如你的任务是要写入到目的端的100个同构分表(表名称为:datax_00,datax01, ... datax_98,datax_99),并且你希望导入数据前,先对表中数据进行删除操作,那么你可以这样配置:"preSql":["delete from 表名"],效果是:在执行到每个表写入数据前,会先执行对应的 delete from 对应表名称
postSql
类型: 富文本
必须: 否
默认值: 无
说明:
写入数据到目的表后,会执行这里的标准语句。(原理同 preSql )
session
类型: 富文本
必须: 否
默认值: 无
说明:
DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性
自动建表
类型: 单选
必须: 是
默认值: on
说明:
解析Reader的元数据,自动生成Writer create table DDL语句,有三种选择:
off:关闭自动生成及同步目标端建表DDL语句,当目标端表实例已经存在可选择此选项。default:打开动生成及自动执行目标端建表DDL语句,执行任务状态由程序自动控制毋需人为干涉。customized:用户可自定义设置自动执行目标端建表DDL语句逻辑,如:是否需要生成列注释等。
batchSize
类型: 整型数字
必须: 否
默认值: 1000
说明:
- 描述:一次性批量提交的记录数大小,该值可以极大减少DataX与Mysql的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进程OOM情况。
配置模版
- 类型: 富文本
- 必须: 是
- 默认值: com.qlangtech.tis.plugin.datax.DataxMySQLWriter.getDftTemplate()
- 说明: 无特殊情况请不要修改模版内容,避免不必要的错误
实时读
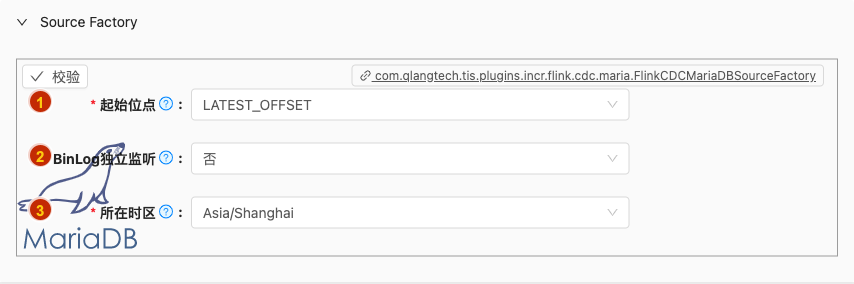
- 配置项说明:
起始位点
类型: 单选
必须: 是
默认值: LATEST_OFFSET
说明:
Debezium startup options
参数详细请参考:https://ververica.github.io/flink-cdc-connectors/master/content/connectors/mysql-cdc.html#connector-options ,https://debezium.io/documentation/reference/1.5/connectors/mysql.html#mysql-property-snapshot-mode
Initial: Performs an initial snapshot on the monitored database tables upon first startup, and continue to read the latest binlog.Earliest: Never to perform snapshot on the monitored database tables upon first startup, just read from the beginning of the binlog. This should be used with care, as it is only valid when the binlog is guaranteed to contain the entire history of the database.Latest: Never to perform snapshot on the monitored database tables upon first startup, just read from the end of the binlog which means only have the changes since the connector was started.Timestamp: Never to perform snapshot on the monitored database tables upon first startup, and directly read binlog from the specified timestamp.The consumer will traverse the binlog from the beginning and ignore change events whose timestamp is smaller than the specified timestamp.
BinLog独立监听
类型: 单选
必须: 是
默认值: false
说明:
执行Flink任务过程中,Binlog监听分配独立的Slot计算资源不会与下游计算算子混合在一起。
如开启,带来的好处是运算时资源各自独立不会相互相互影响,弊端是,上游算子与下游算子独立在两个Solt中需要额外的网络传输开销
所在时区
- 类型: 单选
- 必须: 是
- 默认值: com.qlangtech.tis.plugins.incr.flink.cdc.mysql.FlinkCDCMySQLSourceFactory.dftZoneId()
- 说明: 设置MySQL服务端所在时区
实时写
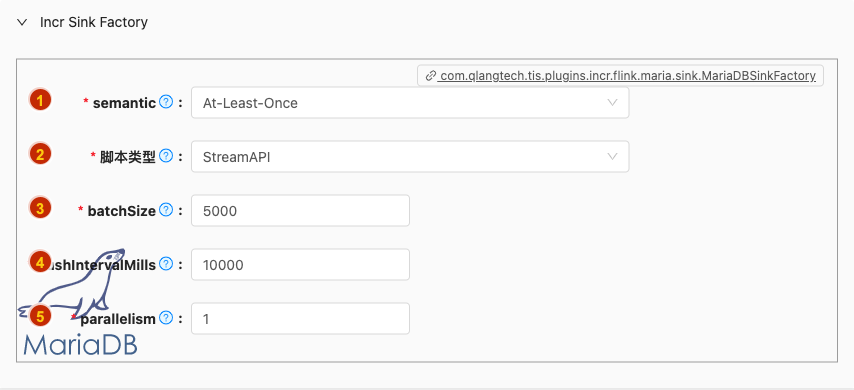
- 配置项说明:
semantic
类型: 单选
必须: 是
默认值: at-least-once
说明:
描述: sink 端是否支持二阶段提交
注意: 如果此参数为空,默认不开启二阶段提交,即 sink 端不支持 exactly_once 语义; 当前只支持 exactly-once 和 at-least-once
脚本类型
类型: 单行文本
必须: 是
默认值: StreamAPI
说明:
TIS 为您自动生成 Flink Stream 脚本,现支持两种类型脚本:
SQL: 优点逻辑清晰,便于用户自行修改执行逻辑Stream API:优点基于系统更底层执行逻辑执行、轻量、高性能
batchSize
类型: 整型数字
必须: 是
默认值: 5000
说明:
描述:一次性批量提交的记录数大小,该值可以极大减少 ChunJun 与数据库的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成 ChunJun 运行进程 OOM 情况
flushIntervalMills
- 类型: 整型数字
- 必须: 是
- 默认值: 10000
- 说明: "the flush interval mills, over this time, asynchronous threads will flush data. The default value is 10s.
parallelism
- 类型: 整型数字
- 必须: 是
- 默认值: 1
- 说明: sink 并行度