Flink
flink-cluster
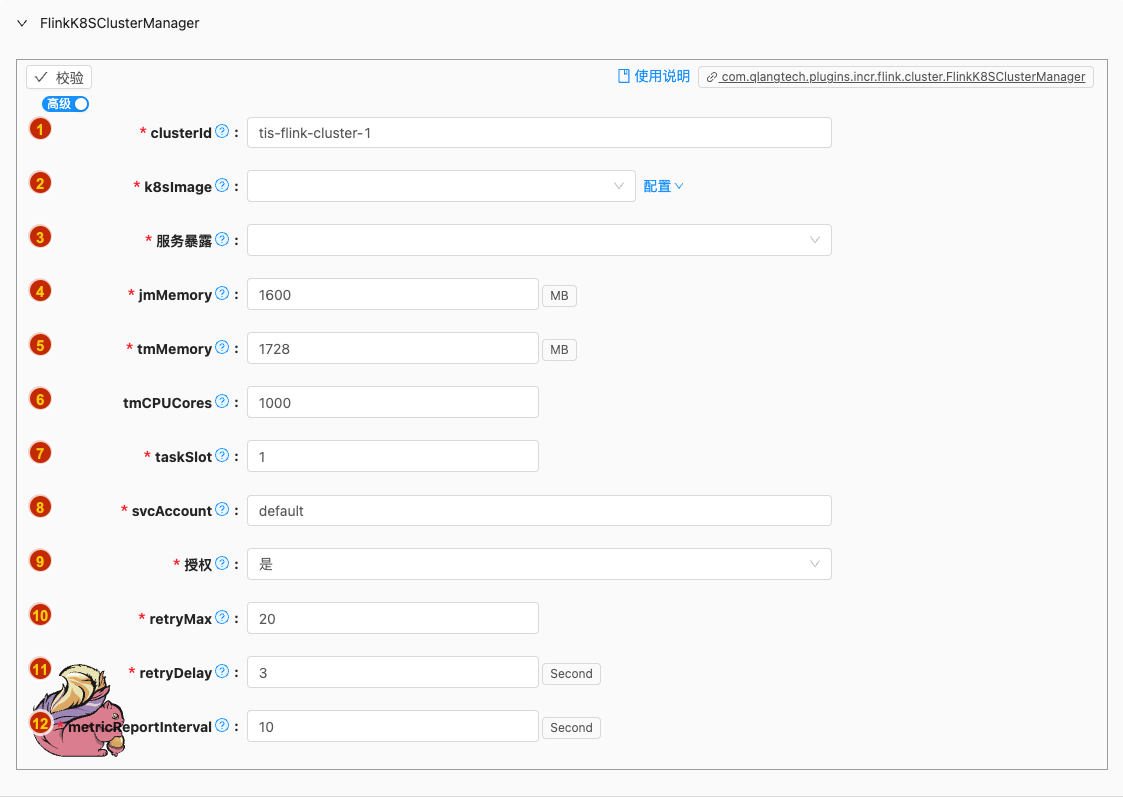
- 配置项说明:
clusterId
类型: 单行文本
必须: 是
默认值: tis-flink-cluster-1
说明:
The cluster-id, which should be no more than 45 characters, is used for identifying a unique Flink cluster. The id must only contain lowercase alphanumeric characters and "-". The required format is
a-z. If not set, the client will automatically generate it with a random ID.The
cluster-id, which should be no more than 45 characters, is used for identifying a unique Flink cluster.
k8sImage
- 类型: 单选
- 必须: 是
- 默认值: flink-cluster
- 说明: 选择一个与该执行器匹配的Docker Image实例
服务暴露
类型: 整型数字
必须: 是
默认值: 无
说明: Flink集群 启动之后将默认8081端口对外部暴露,可选择K8S相应暴露服务端口方式,如:NodePort,Ingress,LoadBalance
可选项说明: 可选
Ingress,LoadBalance,NodePort以下是详细说明:Ingress

- 配置项说明:
serverPort
- 类型: 整型数字
- 必须: 是
- 默认值: com.qlangtech.tis.trigger.util.UnCacheString@6d9ee75a
- 说明: SpringBoot配置,HTTP端口号,默认7700,不建议更改
host
- 类型: 单行文本
- 必须: 是
path
- 类型: 单行文本
- 必须: 是
LoadBalance

- 配置项说明:
serverPort
- 类型: 整型数字
- 必须: 是
- 默认值: com.qlangtech.tis.trigger.util.UnCacheString@2befb16f
- 说明: SpringBoot配置,HTTP端口号,默认7700,不建议更改
NodePort
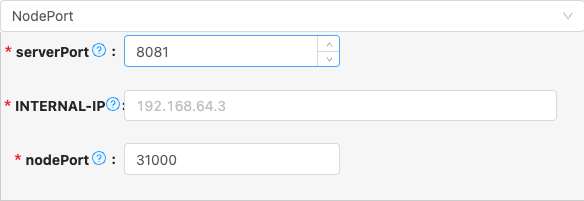
- 配置项说明:
serverPort
- 类型: 整型数字
- 必须: 是
- 默认值: com.qlangtech.tis.trigger.util.UnCacheString@cd93621
- 说明: SpringBoot配置,HTTP端口号,默认7700,不建议更改
INTERNAL-IP
类型: 单行文本
必须: 是
默认值: 无
说明:
通过执行如下命令:
kubectl get nodes -o wide得到如下输出结果:
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
baisui-test-2 Ready control-plane 242d v1.28.3 192.168.28.201 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://24.0.5可
任选一条记录的INTERNAL-IP填入输入框中
nodePort
类型: 整型数字
必须: 是
默认值: 31000
说明:
NodePort服务是让外部请求直接访问服务的最原始方式,NodePort是在所有的节点上开放指定的端口,所有发送到这个端口的请求都会直接转发到服务中的pod里;
这种方式不足:
- 一个端口只提供一个服务使用
- 只能使用30000-32767之间的端口
- 如果节点/虚拟机的IP地址发送变化,需要人工处理;
所以在生产环境,不推荐这种方式发布服务
jmMemory
类型: 字节规格容量
必须: 是
默认值: 1600
说明:
Total Process Memory size for the JobManager. This includes all the memory that a JobManager JVM process consumes, consisting of Total Flink Memory, JVM Metaspace, and JVM Overhead. In containerized setups, this should be set to the container memory. See also 'jobmanager.memory.flink.size' for Total Flink Memory size configuration.
单位:
mbTotal Process Memory size for the JobManager.This includes all the memory that a JobManager JVM process consumes, consisting of Total Flink Memory, JVM Metaspace, and JVM Overhead. In containerized setups, this should be set to the container memory. See also 'jobmanager.memory.flink.size' for Total Flink Memory size configuration.
tmMemory
类型: 字节规格容量
必须: 是
默认值: 1728
说明:
Total Process Memory size for the TaskExecutors. This includes all the memory that a TaskExecutor consumes, consisting of Total Flink Memory, JVM Metaspace, and JVM Overhead. On containerized setups, this should be set to the container memory. See also 'taskmanager.memory.flink.size' for total Flink memory size configuration.
单位:
mbTotal Flink Memory size for the TaskExecutors.This includes all the memory that a TaskExecutor consumes, except for JVM Metaspace and JVM Overhead. It consists of Framework Heap Memory, Task Heap Memory, Task Off-Heap Memory, Managed Memory, and Network Memory. See also '%s' for total process memory size configuration.
tmCPUCores
类型: 整型数字
必须: 否
默认值: 1000
说明:
CPU cores for the TaskExecutors. In case of Yarn setups, this value will be rounded to the closest positive integer. If not explicitly configured, legacy config options 'yarn.containers.vcores' and 'kubernetes.taskmanager.cpu' will be used for Yarn / Kubernetes setups, and 'taskmanager.numberOfTaskSlots' will be used for standalone setups (approximate number of slots).
*1000个单位代表一个1 CPU Core
taskSlot
类型: 整型数字
必须: 是
默认值: 1
说明:
The number of parallel operator or user function instances that a single TaskManager can run. If this value is larger than 1, a single TaskManager takes multiple instances of a function or operator. That way, the TaskManager can utilize multiple CPU cores, but at the same time, the available memory is divided between the different operator or function instances. This value is typically proportional to the number of physical CPU cores that the TaskManager's machine has (e.g., equal to the number of cores, or half the number of cores).
svcAccount
类型: 单行文本
必须: 是
默认值: default
说明:
Service account that is used by jobmanager and taskmanager within kubernetes cluster. Notice that this can be overwritten by config options 'kubernetes.jobmanager.service-account' and 'kubernetes.taskmanager.service-account' for jobmanager and taskmanager respectively.
授权
类型: 单选
必须: 是
默认值: true
说明:
保证Flink 在Kubernetes(Session / Application)模式下拥有执行所有操作都有相应的权限,如不拥有相应权限则会报以下错误:
io.fabric8.kubernetes.client.KubernetesClientException: pods is forbidden:
User "system:serviceaccount:default:default" cannot watch resource "pods" in API group "" in the namespace "default"如选择:是,执行过程会查看系统是否有 rolebing:tis-flink-manager,如没有,则会在Kubernetes Cluster中执行以下等效语句:
kubectl create clusterrolebinding tis-flink-manager --clusterrole=cluster-admin --serviceaccount=default:default
retryMax
类型: 整型数字
必须: 是
默认值: 20
说明:
The number of retries the client will attempt if a retryable operations fails.
retryDelay
类型: 时间跨度
必须: 是
默认值: 3
说明:
The time that the client waits between retries (See also
rest.retry.max-attempts).单位:
秒
metricReportInterval
类型: 时间跨度
必须: 是
默认值: 10
说明:
The reporter interval to use for the reporter named <name>. Only applicable to push-based reporters.
单位:
秒
flink-kubernetes-application-cfg
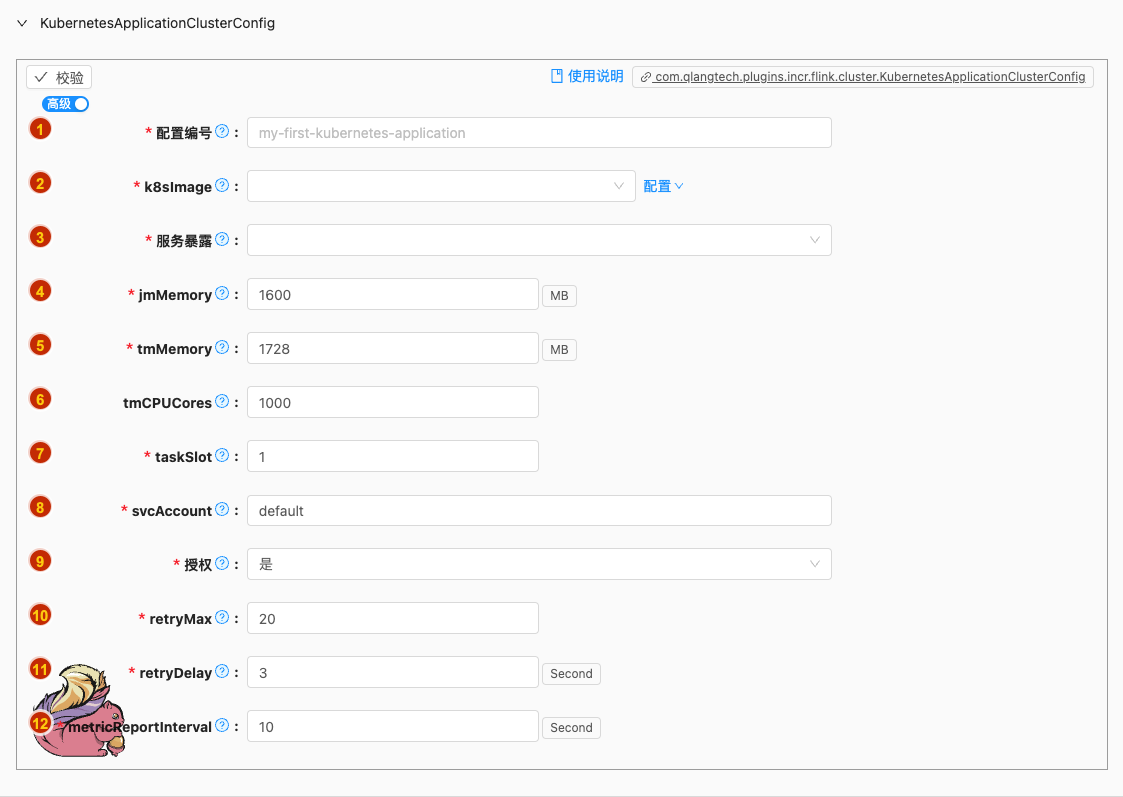
- 配置项说明:
配置编号
- 类型: 单行文本
- 必须: 是
- 默认值: 无
- 说明: 可将此配置作为'kubernetes-application'部署配置模版,作为配置标识后续可供其他kubernetes-application部署类型的Flink Job引用
k8sImage
- 类型: 单选
- 必须: 是
- 默认值: flink-cluster
- 说明: 选择一个与该执行器匹配的Docker Image实例
服务暴露
类型: 整型数字
必须: 是
默认值: 无
说明: Flink集群 启动之后将默认8081端口对外部暴露,可选择K8S相应暴露服务端口方式,如:NodePort,Ingress,LoadBalance
可选项说明: 可选
Ingress,LoadBalance,NodePort以下是详细说明:Ingress
- 配置项说明:
serverPort
- 类型: 整型数字
- 必须: 是
- 默认值: com.qlangtech.tis.trigger.util.UnCacheString@6d9ee75a
- 说明: SpringBoot配置,HTTP端口号,默认7700,不建议更改
host
- 类型: 单行文本
- 必须: 是
path
- 类型: 单行文本
- 必须: 是
LoadBalance
- 配置项说明:
serverPort
- 类型: 整型数字
- 必须: 是
- 默认值: com.qlangtech.tis.trigger.util.UnCacheString@2befb16f
- 说明: SpringBoot配置,HTTP端口号,默认7700,不建议更改
NodePort
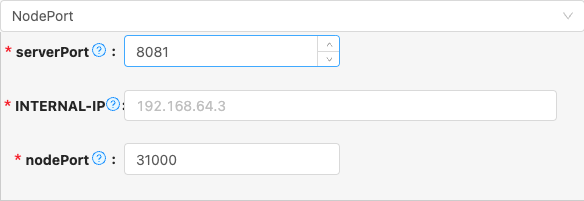
- 配置项说明:
serverPort
- 类型: 整型数字
- 必须: 是
- 默认值: com.qlangtech.tis.trigger.util.UnCacheString@cd93621
- 说明: SpringBoot配置,HTTP端口号,默认7700,不建议更改
INTERNAL-IP
类型: 单行文本
必须: 是
默认值: 无
说明:
通过执行如下命令:
kubectl get nodes -o wide得到如下输出结果:
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
baisui-test-2 Ready control-plane 242d v1.28.3 192.168.28.201 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://24.0.5可
任选一条记录的INTERNAL-IP填入输入框中
nodePort
类型: 整型数字
必须: 是
默认值: 31000
说明:
NodePort服务是让外部请求直接访问服务的最原始方式,NodePort是在所有的节点上开放指定的端口,所有发送到这个端口的请求都会直接转发到服务中的pod里;
这种方式不足:
- 一个端口只提供一个服务使用
- 只能使用30000-32767之间的端口
- 如果节点/虚拟机的IP地址发送变化,需要人工处理;
所以在生产环境,不推荐这种方式发布服务
jmMemory
类型: 字节规格容量
必须: 是
默认值: 1600
说明:
Total Process Memory size for the JobManager. This includes all the memory that a JobManager JVM process consumes, consisting of Total Flink Memory, JVM Metaspace, and JVM Overhead. In containerized setups, this should be set to the container memory. See also 'jobmanager.memory.flink.size' for Total Flink Memory size configuration.
单位:
mb
tmMemory
类型: 字节规格容量
必须: 是
默认值: 1728
说明:
Total Process Memory size for the TaskExecutors. This includes all the memory that a TaskExecutor consumes, consisting of Total Flink Memory, JVM Metaspace, and JVM Overhead. On containerized setups, this should be set to the container memory. See also 'taskmanager.memory.flink.size' for total Flink memory size configuration.
单位:
mb
tmCPUCores
类型: 整型数字
必须: 否
默认值: 1000
说明:
CPU cores for the TaskExecutors. In case of Yarn setups, this value will be rounded to the closest positive integer. If not explicitly configured, legacy config options 'yarn.containers.vcores' and 'kubernetes.taskmanager.cpu' will be used for Yarn / Kubernetes setups, and 'taskmanager.numberOfTaskSlots' will be used for standalone setups (approximate number of slots).
*1000个单位代表一个1 CPU Core
taskSlot
类型: 整型数字
必须: 是
默认值: 1
说明:
The number of parallel operator or user function instances that a single TaskManager can run. If this value is larger than 1, a single TaskManager takes multiple instances of a function or operator. That way, the TaskManager can utilize multiple CPU cores, but at the same time, the available memory is divided between the different operator or function instances. This value is typically proportional to the number of physical CPU cores that the TaskManager's machine has (e.g., equal to the number of cores, or half the number of cores).
svcAccount
类型: 单行文本
必须: 是
默认值: default
说明:
Service account that is used by jobmanager and taskmanager within kubernetes cluster. Notice that this can be overwritten by config options 'kubernetes.jobmanager.service-account' and 'kubernetes.taskmanager.service-account' for jobmanager and taskmanager respectively.
授权
类型: 单选
必须: 是
默认值: true
说明:
保证Flink 在Kubernetes(Session / Application)模式下拥有执行所有操作都有相应的权限,如不拥有相应权限则会报以下错误:
io.fabric8.kubernetes.client.KubernetesClientException: pods is forbidden:
User "system:serviceaccount:default:default" cannot watch resource "pods" in API group "" in the namespace "default"如选择:是,执行过程会查看系统是否有 rolebing:tis-flink-manager,如没有,则会在Kubernetes Cluster中执行以下等效语句:
kubectl create clusterrolebinding tis-flink-manager --clusterrole=cluster-admin --serviceaccount=default:default
retryMax
类型: 整型数字
必须: 是
默认值: 20
说明:
The number of retries the client will attempt if a retryable operations fails.
retryDelay
类型: 时间跨度
必须: 是
默认值: 3
说明:
The time that the client waits between retries (See also
rest.retry.max-attempts).单位:
秒
metricReportInterval
类型: 时间跨度
必须: 是
默认值: 10
说明:
The reporter interval to use for the reporter named <name>. Only applicable to push-based reporters.
单位:
秒
Flink
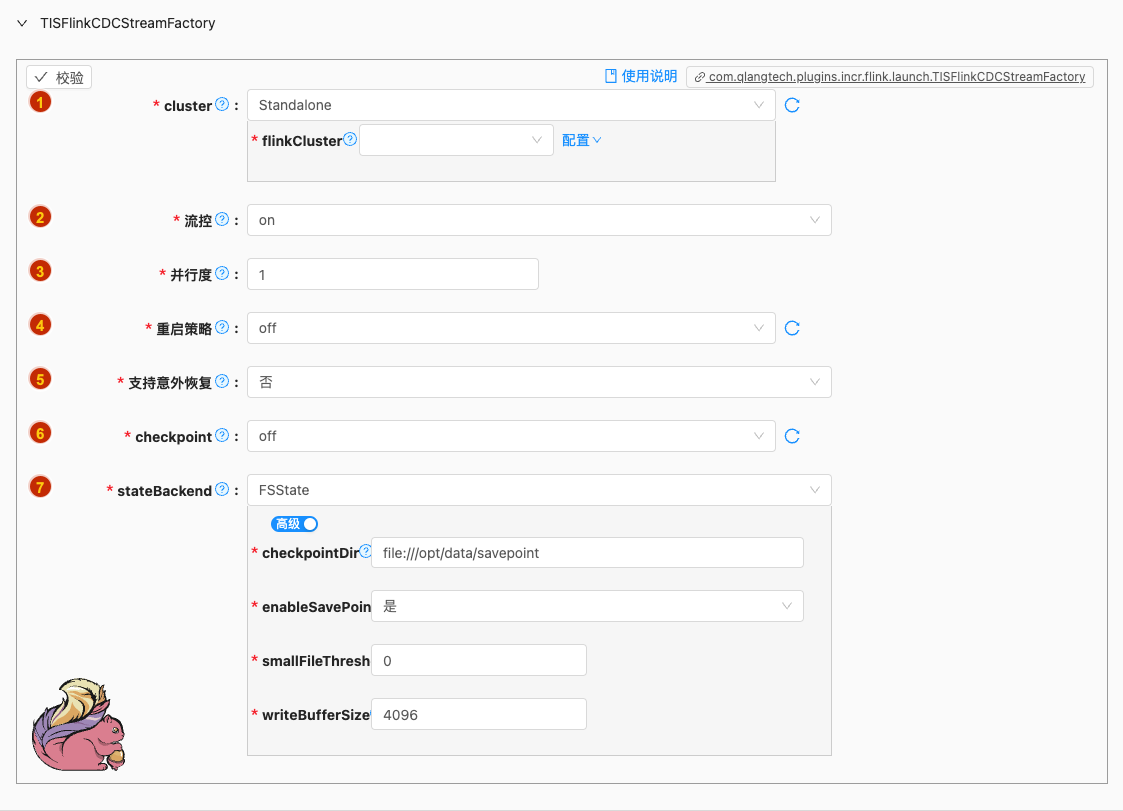
- 配置项说明:
cluster
类型: 单行文本
必须: 是
默认值: Standalone
说明:
对应Flink的执行任务集群,TIS组装好Flink Job之后,提交任务时会向 Flink Cluster中提交任务。
TIS平台中,提交任务前,请先创建Flink Cluster,其支持三种部署模式:
Kubernetes Session: 详细请查看
特点是多个Flink Job任务会由同一个Job Manager分配资源调度
Kubernetes Application: 详细请查看 Application Mode Detail
每个Flink Job任务独占一个JobManager ,对于运行在集群中的Job不会有资源抢占问题,
因此对于比较重要且优先级的任务,建议采用这种部署方式
可选项说明: 可选
Standalone,kubernetes-application,kubernetes-session以下是详细说明:Standalone

- 配置项说明:
flinkCluster
类型: 单选
必须: 是
默认值: 无
说明:
Standalone 集群: 详细请查看
安装说明:
下载、解压
wget http://tis-release.oss-cn-beijing.aliyuncs.com/5.0.0/tis/flink-tis-1.20.1-bin.tar.gz && rm -rf flink-tis-1.20.1 && mkdir flink-tis-1.20.1 && tar xvf flink-tis-1.20.1-bin.tar.gz -C ./flink-tis-1.20.1修改
$FLINK_HOME/conf/config.yaml# The address that the REST & web server binds to
# By default, this is localhost, which prevents the REST & web server from
# being able to communicate outside of the machine/container it is running on.
#
# To enable this, set the bind address to one that has access to outside-facing
# network interface, such as 0.0.0.0.
#
rest.bind-address: 0.0.0.0这样使Flink启动之后,可以从其他机器节点访问flink所在的节点
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager:
numberOfTaskSlots: 1默认值是1,需要在单个Flink节点上运行多个Flink任务,可修改成大于1的值就行(一般情况slot代表了服务节点的资源并行处理能力,一般配置于节点CPU核数相一致即可)
启动Flink-Cluster:
./bin/start-cluster.sh
kubernetes-application

- 配置项说明:
clusterId
类型: 单行文本
必须: 是
默认值: tis-flink-cluster-1
说明:
The cluster-id, which should be no more than 45 characters, is used for identifying a unique Flink cluster. The id must only contain lowercase alphanumeric characters and "-". The required format is
a-z. If not set, the client will automatically generate it with a random ID.
集群配置
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 管理已创建的集群配置引用,如还未创建则不选,在下一步流程中创建集群配置
kubernetes-session

- 配置项说明:
flinkCluster
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 无
流控
类型: 单行文本
必须: 是
默认值: on
说明:
用于运行期 限流读取数据 的控制实现,其主要目的是控制数据源的读取速率 ,防止反压(Backpressure),避免下游系统过载或资源耗尽,可避免因数据消费过快导致内存溢出(OOM)或 CPU/网络带宽被占满。
打开流控开关,选择
on就可在任务运行期,对流选择以下三种控制类型:- 任务
暂停/恢复功能 - 设置每秒消息限流数目
- 取消每秒消息限流阀
- 任务
可选项说明: 可选
off,on以下是详细说明:off
on
并行度
类型: 整型数字
必须: 是
默认值: 1
说明:
任务执行并行度
在 Flink 里面代表每个任务的并行度,适当的提高并行度可以大大提高 job 的执行效率,比如你的 job 消费 kafka 数据过慢,适当调大可能就消费正常了。
重启策略
类型: 单行文本
必须: 是
默认值: off
说明:
The cluster can be started with a default restart strategy which is always used when no job specific restart strategy has been defined. In case that the job is submitted with a restart strategy, this strategy overrides the cluster’s default setting.
Detailed description:restart-strategies
There are 4 types of restart-strategy:
可选项说明: 可选
exponential-delay,failure-rate,fixed-delay,off以下是详细说明:exponential-delay
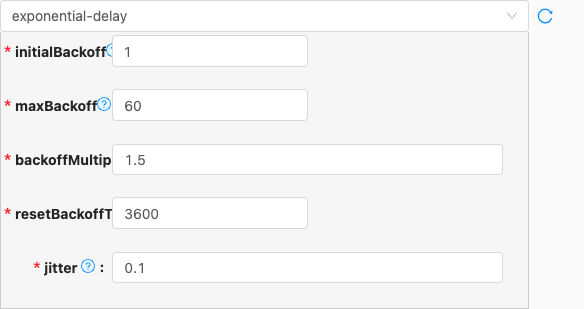
- 配置项说明:
initialBackoff
类型: 整型数字
必须: 是
默认值: 1
说明:
Starting duration between restarts if
restart-strategy.typehas been set toexponential-delay. It can be specified using notation: "1 min", "20 s"单位:
秒
maxBackoff
类型: 整型数字
必须: 是
默认值: 60
说明:
The highest possible duration between restarts if
restart-strategy.typehas been set toexponential-delay. It can be specified using notation: "1 min", "20 s"单位:
秒
backoffMultiplier
类型: 单行文本
必须: 是
默认值: 1.5
说明:
Backoff value is multiplied by this value after every failure,until max backoff is reached if
restart-strategy.typehas been set toexponential-delay.
resetBackoffThreshold
类型: 整型数字
必须: 是
默认值: 3600
说明:
Threshold when the backoff is reset to its initial value if
restart-strategy.typehas been set toexponential-delay. It specifies how long the job must be running without failure to reset the exponentially increasing backoff to its initial value. It can be specified using notation: "1 min", "20 s"单位:
秒
jitter
类型: 单行文本
必须: 是
默认值: 0.1
说明:
Jitter specified as a portion of the backoff if
restart-strategy.typehas been set toexponential-delay. It represents how large random value will be added or subtracted to the backoff. Useful when you want to avoid restarting multiple jobs at the same time.
failure-rate
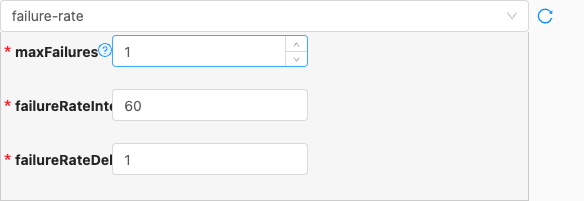
- 配置项说明:
maxFailures
类型: 整型数字
必须: 是
默认值: 1
说明:
Maximum number of restarts in given time interval before failing a job if
restart-strategy.typehas been set tofailure-rate.
failureRateInterval
类型: 整型数字
必须: 是
默认值: 60
说明:
Time interval for measuring failure rate if
restart-strategy.typehas been set tofailure-rate. It can be specified using notation: "1 min", "20 s"单位:
秒
failureRateDelay
类型: 整型数字
必须: 是
默认值: 1
说明:
Delay between two consecutive restart attempts if
restart-strategy.typehas been set tofailure-rate. It can be specified using notation: "1 min", "20 s"单位:
秒
fixed-delay

- 配置项说明:
attempts
类型: 整型数字
必须: 是
默认值: 1
说明:
The number of times that Flink retries the execution before the job is declared as failed if
restart-strategy.typehas been set tofixed-delay.
delay
类型: 整型数字
必须: 是
默认值: 1
说明:
Delay between two consecutive restart attempts if
restart-strategy.typehas been set tofixed-delay. Delaying the retries can be helpful when the program interacts with external systems where for example connections or pending transactions should reach a timeout before re-execution is attempted. It can be specified using notation: "1 min", "20 s"单位:
秒
off
支持意外恢复
类型: 单选
必须: 是
默认值: false
说明:
支持任务恢复,当Flink节点因为服务器意外宕机导致当前运行的flink job意外终止,需要支持Flink Job恢复执行,
需要Flink配置支持:
- 持久化stateBackend
- 开启checkpoint
checkpoint
类型: 单行文本
必须: 是
默认值: off
说明:
Checkpoints make state in Flink fault tolerant by allowing state and the corresponding stream positions to be recovered, thereby giving the application the same semantics as a failure-free execution.
Detailed description:
可选项说明: 可选
customize,off,on以下是详细说明:customize
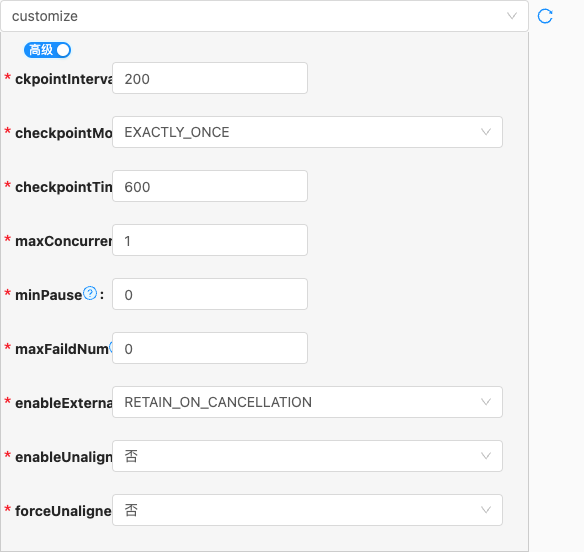
- 配置项说明:
ckpointInterval
类型: 整型数字
必须: 是
默认值: 200
说明:
Gets the interval in which checkpoints are periodically scheduled.
This setting defines the base interval. Checkpoint triggering may be delayed by the settingsexecution.checkpointing.max-concurrent-checkpoints,execution.checkpointing.min-pauseandexecution.checkpointing.interval-during-backlog单位:
秒
checkpointMode
类型: 单选
必须: 是
默认值: EXACTLY_ONCE
说明:
The checkpointing mode (exactly-once vs. at-least-once).
checkpointTimeout
类型: 整型数字
必须: 是
默认值: 600
说明:
The maximum time that a checkpoint may take before being discarded.
单位:
秒
maxConcurrentNum
类型: 整型数字
必须: 是
默认值: 1
说明:
The maximum number of checkpoint attempts that may be in progress at the same time. If this value is n, then no checkpoints will be triggered while n checkpoint attempts are currently in flight. For the next checkpoint to be triggered, one checkpoint attempt would need to finish or expire.
minPause
类型: 整型数字
必须: 是
默认值: 0
说明:
The minimal pause between checkpointing attempts. This setting defines how soon thecheckpoint coordinator may trigger another checkpoint after it becomes possible to triggeranother checkpoint with respect to the maximum number of concurrent checkpoints(see
execution.checkpointing.max-concurrent-checkpoints).
If the maximum number of concurrent checkpoints is set to one, this setting makes effectively sure that a minimum amount of time passes where no checkpoint is in progress at all.单位:
秒
maxFaildNum
类型: 整型数字
必须: 是
默认值: 0
说明:
The tolerable checkpoint consecutive failure number. If set to 0, that means we do not tolerance any checkpoint failure. This only applies to the following failure reasons: IOException on the Job Manager, failures in the async phase on the Task Managers and checkpoint expiration due to a timeout. Failures originating from the sync phase on the Task Managers are always forcing failover of an affected task. Other types of checkpoint failures (such as checkpoint being subsumed) are being ignored.
enableExternal
类型: 单选
必须: 是
默认值: RETAIN_ON_CANCELLATION
说明:
Externalized checkpoints write their meta data out to persistent storage and are not automatically cleaned up when the owning job fails or is suspended (terminating with job status
JobStatus#FAILEDorJobStatus#SUSPENDED). In this case, you have to manually clean up the checkpoint state, both the meta data and actual program state.
The mode defines how an externalized checkpoint should be cleaned up on job cancellation. If you choose to retain externalized checkpoints on cancellation you have to handle checkpoint clean up manually when you cancel the job as well (terminating with job statusJobStatus#CANCELED).
The target directory for externalized checkpoints is configured viaexecution.checkpointing.dir.
enableUnaligned
类型: 单选
必须: 是
默认值: false
说明:
Enables unaligned checkpoints, which greatly reduce checkpointing times under backpressure.
Unaligned checkpoints contain data stored in buffers as part of the checkpoint state, which allows checkpoint barriers to overtake these buffers. Thus, the checkpoint duration becomes independent of the current throughput as checkpoint barriers are effectively not embedded into the stream of data anymore.
Unaligned checkpoints can only be enabled ifexecution.checkpointing.modeisEXACTLY_ONCEand ifexecution.checkpointing.max-concurrent-checkpointsis 1
forceUnaligned
类型: 单选
必须: 是
默认值: false
说明:
Forces unaligned checkpoints, particularly allowing them for iterative jobs.
off
on

- 配置项说明:
ckpointInterval
类型: 整型数字
必须: 是
默认值: 200
说明:
Gets the interval in which checkpoints are periodically scheduled.
This setting defines the base interval. Checkpoint triggering may be delayed by the settingsexecution.checkpointing.max-concurrent-checkpoints,execution.checkpointing.min-pauseandexecution.checkpointing.interval-during-backlog单位:
秒
stateBackend
类型: 单行文本
必须: 是
默认值: FSState
说明:
Flink provides different state backends that specify how and where state is stored.
State can be located on Java’s heap or off-heap. Depending on your state backend, Flink can also manage the state for the application, meaning Flink deals with the memory management (possibly spilling to disk if necessary) to allow applications to hold very large state. By default, the configuration file flink-conf.yaml determines the state backend for all Flink jobs.
However, the default state backend can be overridden on a per-job basis, as shown below.
For more information about the available state backends, their advantages, limitations, and configuration parameters see the corresponding section in Deployment & Operations.
可选项说明: 可选
FSState,HashMapState,off以下是详细说明:FSState
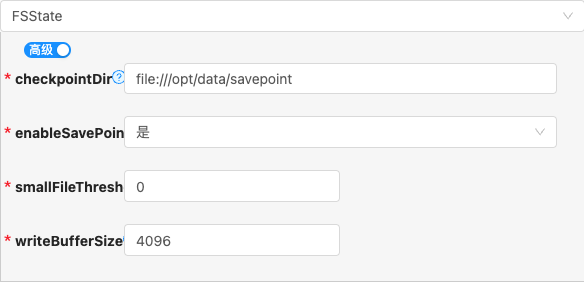
- 配置项说明:
checkpointDir
类型: 单行文本
必须: 是
默认值: file:///opt/data/savepoint
说明:
The default directory used for storing the data files and meta data of checkpoints in a Flink supported filesystem. The storage path must be accessible from all participating processes/nodes(i.e. all TaskManagers and JobManagers). If the 'execution.checkpointing.storage' is set to 'jobmanager', only the meta data of checkpoints will be stored in this directory.
The scheme (hdfs://, file://, etc) is null. Please specify the file system scheme explicitly in the URI.
enableSavePoint
类型: 单选
必须: 是
默认值: true
说明:
支持任务执行savepoint,Flink任务管理器执行停机操作时会主动触发创建savepoint操作,存放位置为属性
checkpointDir平行目录下的一个以时间戳命名的子目录中
smallFileThreshold
类型: 整型数字
必须: 是
默认值: 0
说明:
The minimum size of state data files. All state chunks smaller than that are stored inline in the root checkpoint metadata file. The max memory threshold for this configuration is 1MB.
单位:
mb
writeBufferSize
类型: 整型数字
必须: 是
默认值: 4096
说明:
The default size of the write buffer for the checkpoint streams that write to file systems. The actual write buffer size is determined to be the maximum of the value of this option and option 'execution.checkpointing.data-inline-threshold'.
HashMapState
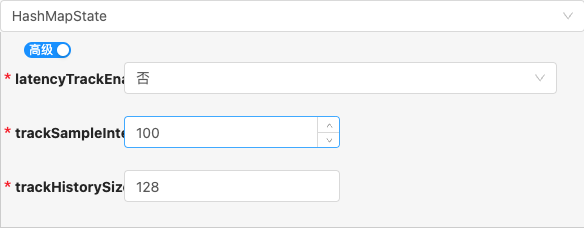
- 配置项说明:
latencyTrackEnable
类型: 单选
必须: 是
默认值: false
说明:
Whether to track latency of keyed state operations, e.g value state put/get/clear.
trackSampleInterval
类型: 整型数字
必须: 是
默认值: 100
说明:
The sample interval of latency track once 'state.backend.latency-track.keyed-state-enabled' is enabled. The default value is 100, which means we would track the latency every 100 access requests.
trackHistorySize
类型: 整型数字
必须: 是
默认值: 128
说明:
Defines the number of measured latencies to maintain at each state access operation.
off
Flink-Cluster
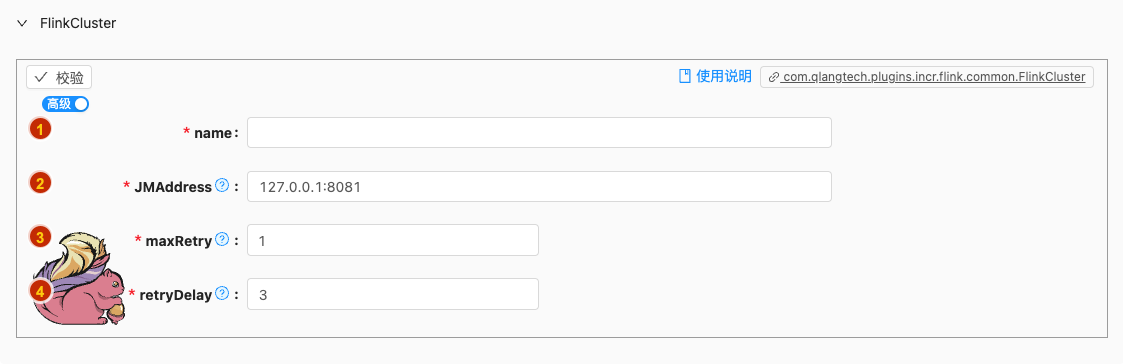
- 配置项说明:
name
- 类型: 单行文本
- 必须: 是
JMAddress
类型: 单行文本
必须: 是
默认值: 127.0.0.1:8081
说明:
The JobManager is serving the web interface accessible at localhost:8081
maxRetry
类型: 整型数字
必须: 是
默认值: 1
说明:
The number of retries the client will attempt if a retryable operations fails.
retryDelay
类型: 整型数字
必须: 是
默认值: 3
说明:
The time that the client waits between retries (See also
rest.retry.max-attempts).单位:
秒