HiveMetaStore
数据源配置
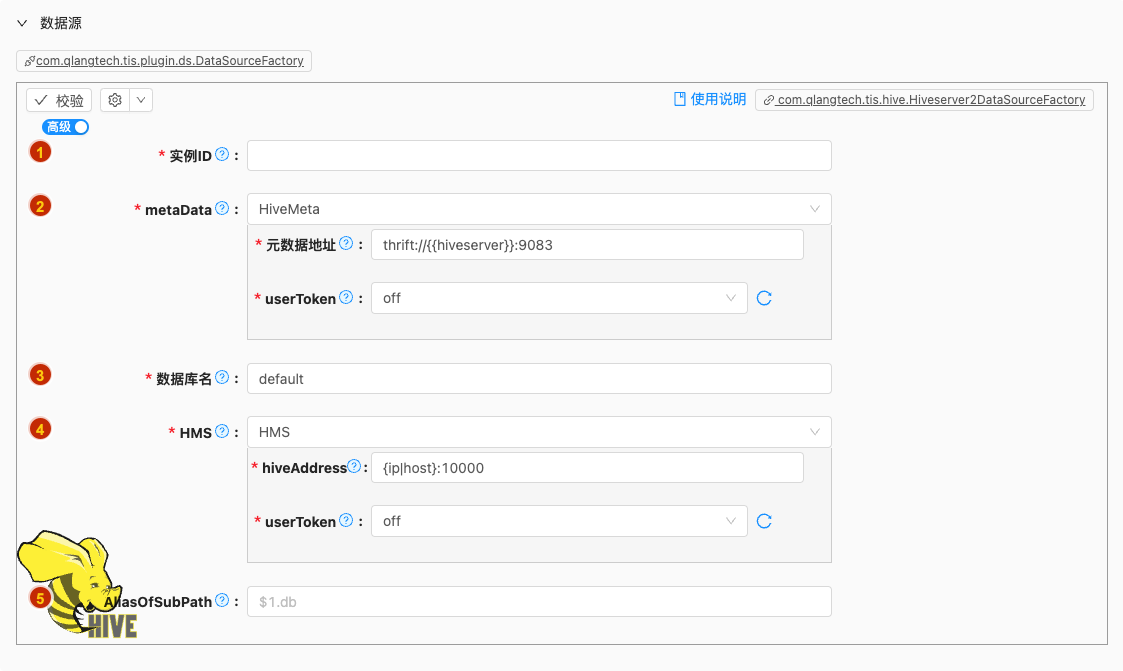
- 配置项说明:
实例ID
- 类型: 单行文本
- 必须: 是
- 默认值: 无
- 说明: 数据源实例名称,请起一个有意义且唯一的名称
metaData
类型: 单行文本
必须: 是
默认值: HiveMeta
说明:
是Hive Metastore服务,其核心作用是管理Hive的元数据(Metadata)。
Hive Metastore 的作用
元数据存储:
- 存储所有Hive表、分区、列、数据类型、存储位置(如HDFS路径)等元数据信息。
- 记录表的创建时间、所有者、权限等管理信息。
元数据共享:
- 允许多个Hive实例(或计算引擎如Spark、Impala)共享同一份元数据,避免重复定义表结构。
- 例如:Spark可以直接通过Hive Metastore读取表结构,无需重新定义表。
解耦元数据与计算:
- Metastore服务独立于HiveServer2,使得元数据管理(9083端口)与查询执行(10000端口)分离,提高系统灵活性和可维护性。
支持多种后端存储:
- 默认使用关系型数据库(如MySQL、PostgreSQL)持久化元数据(而非HDFS),确保元数据的高效查询和事务支持。
可选项说明: 可选
HiveMeta以下是详细说明:HiveMeta
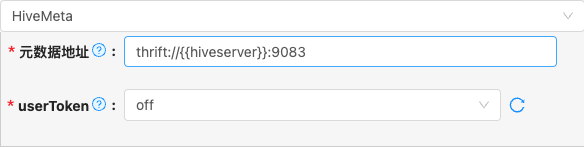
- 配置项说明:
元数据地址
类型: 单行文本
必须: 是
默认值: thrift://{{hiveserver}}:9083
说明:
Hive元数据服务地址,用于获取Hive中存放的表的元数据信息
地址格式如:
thrift://{{hiveserver}}:9083
userToken
- 类型: 单行文本
- 必须: 是
- 默认值: off
- 说明: 当选择为'on', 用户需要填写用户名和密码
数据库名
- 类型: 单行文本
- 必须: 是
- 默认值: default
- 说明: Hive 数据库使用的库名,请在执行任务前先创建完成
HMS
类型: 单行文本
必须: 是
默认值: HMS
说明:
是HiveServer2(HS2)的默认服务,其核心作用是为远程客户端提供与Hive交互,允许远程查询执行:
- 允许客户端(如JDBC、ODBC、Beeline等)通过TCP/IP远程提交HiveQL查询(如SELECT、JOIN等),而无需直接访问Hadoop集群节点。
- 将HiveQL转换为底层计算任务(如MapReduce、Tez、Spark)并提交到集群执行。
可选项说明: 可选
HMS以下是详细说明:HMS

- 配置项说明:
hiveAddress
- 类型: 单行文本
- 必须: 是
- 默认值: {ip|host}:10000
- 说明: 描述:Hive Thrift Server2。格式:ip:端口;例如:127.0.0.1:9000
userToken
- 类型: 单行文本
- 必须: 是
- 默认值: off
- 说明: 当选择为'on', 用户需要填写用户名和密码
AliasOfSubPath
类型: 单行文本
必须: 否
默认值: 无
说明:
假设当前数据库名称为
dezhou,有一张名称为test001的表,默认hdfs上的路径为:hdfs://10.8.0.10:9000/user/hive/warehouse/dezhou/test001而用户的应用场景需要为:
hdfs://10.8.0.10:9000/user/hive/warehouse/dezhou.db/test001此时需要设置此属性为:
$1.db,当然也可以直接设置为:dezhou.db(只不过当dbName变化,此属性不会随之变化)
数据端配置
- 配置项说明:
name
- 类型: 单行文本
- 必须: 是
dbName
- 类型: 单行文本
- 必须: 是
- 默认值: default
- 说明: Hive 数据库使用的库名,请在执行任务前先创建完成
metaStoreUrls
- 类型: 单行文本
- 必须: 是
hiveAddress
- 类型: 单行文本
- 必须: 是
userToken
- 类型: 单行文本
- 必须: 是
批量读
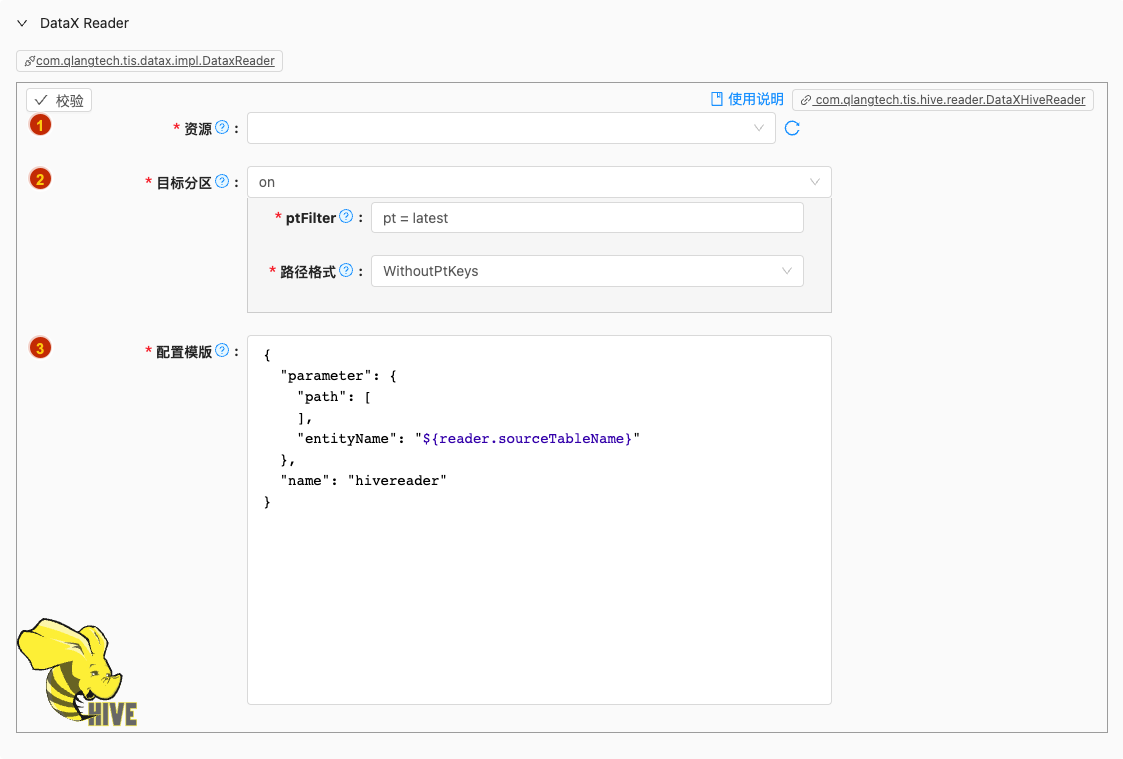
- 配置项说明:
资源
类型: 单行文本
必须: 是
默认值: 无
说明: DFS服务端连接配置
可选项说明: 可选
Hive以下是详细说明:Hive
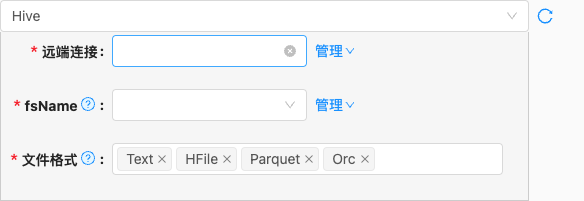
- 配置项说明:
远端连接
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 无
fsName
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 描述:Hadoop hdfs文件系统namenode节点地址。格式:hdfs://ip:端口;例如:hdfs://127.0.0.1:9000
文件格式
- 类型: 单选
- 必须: 是
- 默认值: com.qlangtech.tis.trigger.util.UnCacheString@62c53685
- 说明: 目前支持三种存储格式:Text:普通文本,一行一条用分隔符分隔,HFile:HBase使用的存储格式,Parquet:最常用的列存格式文件,ORC文件格式
目标分区
类型: 单行文本
必须: 是
默认值: on
说明: 如果目标表设置了分区键,请设置该选项
可选项说明: 可选
off,on以下是详细说明:off
on

- 配置项说明:
ptFilter
类型: 单行文本
必须: 是
默认值: com.qlangtech.tis.hive.reader.impl.DefaultPartitionFilter.getPtDftVal()
说明:
每次触发全量读取会使用输入项目的表达式对所有分区进行匹配,默认值为
pt=latest,假设系统中存在两个分区路径:1. pt=20231111121159 , 2. pt=20231211121159很明显
pt=20231211121159为最新分区,会作为目标分区进行读取。用户也可以在输入框中输入
pt=’20231211121159‘强制指定特定分区作为目标分区进行读取。也可以在输入项目中使用过滤条件进行匹配,例如:pt=’20231211121159‘ and pmod='0'
路径格式
类型: 单行文本
必须: 是
默认值: WithoutPtKeys
说明:
支持两种分区路径格式:
WithoutPtKeys: 分区路径上不包含分区字段名,如:/user/hive/warehouse/sales_data/2023/1WithPtKeys:(默认值) 分区路径上包含分区字段名,如:/user/hive/warehouse/sales_data/year=2023/month=1
配置模版
- 类型: 富文本
- 必须: 是
- 默认值: com.qlangtech.tis.hive.reader.DataXHiveReader.getDftTemplate()
- 说明: 无特殊情况请不要修改模版内容,避免不必要的错误
批量写
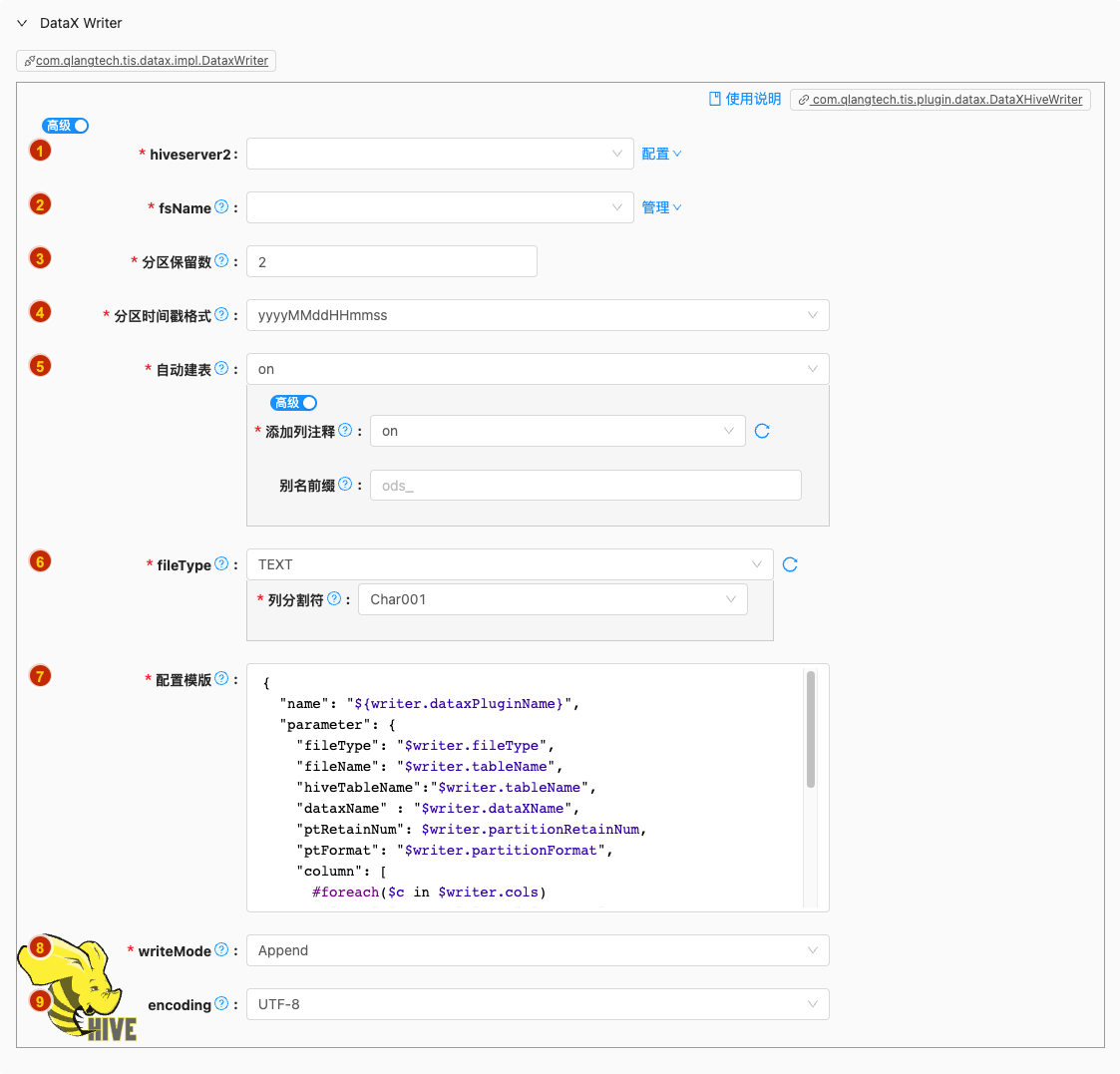
- 配置项说明:
hiveserver2
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 无
fsName
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 描述:Hadoop hdfs文件系统namenode节点地址。格式:hdfs://ip:端口;例如:hdfs://127.0.0.1:9000
分区保留数
类型: 整型数字
必须: 是
默认值: 2
说明:
每进行一次DataX导入在Hive表中会生成一个新的分区,现在系统分区名称为
pt格式为开始导入数据的时间戳
分区时间戳格式
类型: 单选
必须: 是
默认值: yyyyMMddHHmmss
说明:
每进行一次DataX导入在Hive表中会生成一个新的分区,现在系统分区名称为'pt'格式为开始导入数据的当前时间戳,格式为
yyyyMMddHHmmss或者yyyyMMdd
自动建表
类型: 单选
必须: 是
默认值: on
说明: 解析Reader的元数据,自动生成Writer create table DDL语句
可选项说明: 可选
off,on以下是详细说明:off

- 配置项说明:
别名前缀
- 类型: 单行文本
- 必须: 否
- 默认值: 无
- 说明: 统一为目标表添加前缀,例如在构建分层数仓用于为ods层目标表统一添加前缀,例如:
ods_erp_
on
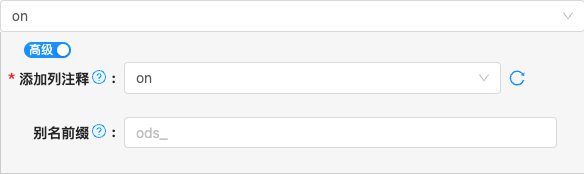
- 配置项说明:
添加列注释
- 类型: 单行文本
- 必须: 是
- 默认值: on
- 说明: 在建表DDL上添加列注释,需要依赖源端表列是否定义注释,如源端列上没有列注释,则目标端建表列DDL上也没有列注释
别名前缀
- 类型: 单行文本
- 必须: 否
- 默认值: 无
- 说明: 统一为目标表添加前缀,例如在构建分层数仓用于为ods层目标表统一添加前缀,例如:
ods_erp_
fileType
类型: 单行文本
必须: 是
默认值: TEXT
说明: 描述:文件的类型,目前只支持用户配置为"text"
可选项说明: 可选
ORC,PARQUET,TEXT以下是详细说明:ORC
PARQUET
TEXT

- 配置项说明:
列分割符
- 类型: 单选
- 必须: 是
- 默认值: char001
- 说明: 描述:读取的字段分隔符,可以用'\t','\001'等字符
配置模版
- 类型: 富文本
- 必须: 是
- 默认值: com.qlangtech.tis.plugin.datax.DataXHiveWriter.getDftTemplate()
- 说明: 无特殊情况请不要修改模版内容,避免不必要的错误
writeMode
类型: 单选
必须: 是
默认值: append
说明:
hdfswriter写入前数据清理处理模式:
- append: 写入前不做任何处理,DataX hdfswriter直接使用filename写入,并保证文件名不冲突,
- nonConflict:如果目录下有fileName前缀的文件,直接报错
encoding
- 类型: 单选
- 必须: 否
- 默认值: utf-8
- 说明: 描述:写文件的编码配置。