Paimon
批量写
- 配置项说明:
catalog
类型: 单行文本
必须: 是
默认值: Hive
说明: 无
可选项说明: 可选
Hive以下是详细说明:Hive

- 配置项说明:
hiveserver2
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 无
fsName
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 描述:Hadoop hdfs文件系统namenode节点地址。格式:hdfs://ip:端口;例如:hdfs://127.0.0.1:9000
commit.user-prefix
类型: 单行文本
必须: 是
默认值: admin
说明:
Specifies the commit user prefix.
在 Paimon 中的作用是标识提交操作的来源,虽然看似可以配置任意值,但它在分布式环境中对运维监控至关重要。 以下是详细解析:
- 核心作用:提交者身份标识
- 分布式环境追踪,在 Flink 集群中,不同 TaskManager 上的写入任务会产生各自的提交记录。通过前缀可快速区分
Lock
- 类型: 单行文本
- 必须: 是
- 默认值: off
- 说明: Enable Catalog Lock.
Cache
- 类型: 单行文本
- 必须: 是
- 默认值: off
- 说明: Controls whether the catalog will cache databases, tables, manifests and partitions.
writeBuffer
类型: 单行文本
必须: 是
默认值: default
说明:
在 Apache Paimon 中,控制底层(特别是 Level 0)小文件大小的核心参数直接影响着 Compaction 的触发频率。通过适当增加单个文件中存储的记录条数(或文件大小),确实可以有效减少 L0 层小文件的数量,从而降低 Compaction 被触发的频率。
以下是控制 L0 层小文件大小和记录数的关键参数及其工作原理:
🧩 1. 核心控制参数:
write-buffer-size和target-file-sizewrite-buffer-size(默认值: 128mb):作用: 这是控制内存中 Buffer 大小的参数。当 Flink 或 Spark 任务向 Paimon 写入数据时,数据首先会缓存在内存中的一个排序缓冲区(Sorter Buffer)中。
原理: 当一个 Buffer 被填满(达到
write-buffer-size)时,它会被排序并刷写(Spill)到磁盘,形成一个 L0 文件。影响:
write-buffer-size直接决定了单个 L0 文件的最小期望大小。如果你期望每个 L0 文件大约是 256MB,那么就应该设置write-buffer-size=256mb。Buffer 满了就刷写,自然就生成了一个 ~256MB 的文件。target-file-size(默认值: 128mb):作用: 这是 Paimon 最终期望生成的稳定数据文件(通常是经过 Compaction 合并到更高层级的文件)的目标大小。
原理: 在 Compaction 过程中(无论是 Universal 还是 Size-Tiered),Paimon 会尝试将输入的小文件合并,并输出大小接近
target-file-size的文件到更高的层级(如 L1, L2)。影响 L0 的间接方式: 虽然
target-file-size主要影响 Compaction 的输出,但它间接影响 L0 文件的“合并潜力”。如果target-file-size设置得很大(比如 1GB),那么 Compaction 需要积累更多的 L0 小文件(累计大小达到 ~1GB)才会触发合并操作。这相当于放宽了触发 Compaction 的“累计大小”阈值。注意:
target-file-size不直接控制单个 L0 文件的大小。L0 文件大小主要由write-buffer-size和 Checkpointing 决定。
🧩 2. 其他影响 L0 文件大小和记录数的因素
Checkpointing / Commit Interval (Flink Streaming):
在 Flink 流式写入场景下,Flink 的 Checkpoint 间隔是决定 L0 文件大小和数量的最关键因素之一。
原理: Paimon 的 Sink 算子通常会在 Flink Checkpoint 时执行
snapshotState。为了确保精确一次的语义,当前内存 Buffer 中的数据(即使未达到write-buffer-size)也会在 Checkpoint 时强制刷写到磁盘,生成一个 L0 文件。影响: 如果 Flink 的 Checkpoint 间隔(
checkpoint.interval)很短(例如 10 秒),即使write-buffer-size设置为 256MB,也可能因为每个 Checkpoint 只积累了少量数据(比如 50MB)就被强制刷出,从而导致产生大量远小于write-buffer-size的 L0 小文件。结论:要减少 L0 小文件数量,在流式写入场景下,适当增加 Flink Checkpoint 间隔 (
checkpoint.interval) 是至关重要的,让 Buffer 有更多时间积累接近write-buffer-size的数据量再刷出。但需权衡故障恢复时间(RTO)。sort-spill-threshold(默认值: 未明确设置,通常内部管理):这个参数控制内存排序缓冲区在内存中最多能容纳多少行数据。当行数超过此阈值时,即使 Buffer 的内存占用未达到
write-buffer-size,也可能触发部分数据溢写(Spill)。这主要用于防止 OOM。影响: 如果记录非常大(例如宽表、大 JSON 对象),即使记录数不多,也可能快速占满内存 Buffer (
write-buffer-size) 而刷写。如果记录非常小(例如计数器更新),则sort-spill-threshold可能先达到,导致按记录数刷写。调整sort-spill-threshold主要应对特殊数据分布场景,一般优先调整write-buffer-size和 Checkpoint 间隔。
✅ 如何通过增加文件大小/记录数减少 Compaction 频率
- 增大
write-buffer-size:
- 这是最直接有效的方法。例如,从默认的
128mb增加到256mb或512mb。 - 效果: 每个 L0 文件平均变大(更接近新设置的 buffer size),L0 层积累到触发 Compaction 阈值(如 Universal 的
num-sorted-run.stop-trigger)所需的文件数量变少,从而降低触发频率。 - 注意: 需要确保 TaskManager 有足够的 JVM Heap 或 Managed Memory 来容纳更大的 Buffer。否则可能导致 OOM 或频繁 GC。
- 增大 Flink Checkpoint 间隔 (
checkpoint.interval):
- 对于流式写入,这是避免超小 L0 文件的关键。根据业务容忍的延迟和恢复时间,尽可能增加间隔(例如从 30s 增加到 1min 或 5min)。
- 效果: 显著减少因频繁 Checkpoint 强制刷写产生的远小于
write-buffer-size的微型 L0 文件数量。让大多数 L0 文件大小接近write-buffer-size。
- 增大
target-file-size:
- 例如从
128mb增加到256mb或512mb。 - 效果: 主要在 Universal Compaction 中影响较大。因为 Universal 在合并时会尽量将一组文件合并成一个接近
target-file-size的大文件。增大target-file-size意味着 Compaction 需要积累更多的 L0 文件(总数据量更大)才会触发合并。对于 Size-Tiered,它定义了更高层级文件的大小目标,也间接影响合并策略。 - 注意: 过大的
target-file-size可能影响查询效率(读取大文件可能慢)和 Compaction 本身的资源消耗(合并更大量数据)。
- 调整 Compaction 触发阈值 (如 Universal 的
num-sorted-run.stop-trigger):
- 虽然不是直接控制文件大小,但配合增大文件大小,调整这个阈值效果更好。例如,如果文件平均大了 2 倍,那么将
num-sorted-run.stop-trigger从默认的 5 增加到 8 或 10,可能仍然能保持或延长触发间隔,同时允许 L0 积累更多文件(但总数据量更大),进一步提升读性能。 - 效果: 直接放宽了触发 Compaction 的条件,让 L0 层可以堆积更多的文件(但每个文件更大了)才触发合并。
⚠️ 总结与权衡
- 核心策略: 增大
write-buffer-size并适当增大 Flink Checkpoint 间隔 是减少 L0 小文件数量、从而降低 Compaction 频率的最有效手段。这直接让每个 L0 文件包含更多记录/更大体积。 - 辅助策略: 增大
target-file-size和/或 Compaction 触发阈值(如num-sorted-run.stop-trigger)可以进一步减少 Compaction 频率,因为它们提高了触发合并所需的“数据量”或“文件数”门槛。 - 重要权衡:
- 内存资源: 增大
write-buffer-size会增加每个 Writer Task 的内存需求。 - 故障恢复: 增大 Flink Checkpoint 间隔会增加故障恢复时需要重放的数据量(RTO 可能变长)。
- 读取延迟: 过大的 L0 文件或过少的 Compaction 可能导致查询(尤其是点查)需要扫描更多的 L0 文件,增加读取延迟。需要监控读性能。
- 空间放大: 减少 Compaction 频率可能导致短时间内存在更多冗余数据(旧版本数据、删除标记等),增加存储空间占用(空间放大)。需要配合合理的快照过期策略。
建议: 从调整
write-buffer-size(如 256MB) 和 Flinkcheckpoint.interval(如 1-5分钟) 开始,观察 L0 文件平均大小是否显著增大、Compaction 频率是否下降。再根据效果和资源/延迟情况,考虑是否调整target-file-size或 Compaction 触发参数。务必监控集群资源(内存、CPU)、Compaction 耗时、查询延迟和存储空间变化。📊可选项说明: 可选
customize,default以下是详细说明:customize

- 配置项说明:
size
类型: 字节规格容量
必须: 是
默认值: 256
说明:
Amount of data to build up in memory before converting to a sorted on-disk file.
write-buffer-size(默认值: 128mb):- 作用: 这是控制内存中 Buffer 大小的参数。当 Flink 或 Spark 任务向 Paimon 写入数据时,数据首先会缓存在内存中的一个排序缓冲区(Sorter Buffer)中。
- 原理: 当一个 Buffer 被填满(达到
write-buffer-size)时,它会被排序并刷写(Spill)到磁盘,形成一个 L0 文件。 - 影响:
write-buffer-size直接决定了单个 L0 文件的最小期望大小。如果你期望每个 L0 文件大约是 256MB,那么就应该设置write-buffer-size=256mb。Buffer 满了就刷写,自然就生成了一个 ~256MB 的文件。
spillable
类型: 单选
必须: 否
默认值: 无
说明:
Whether the write buffer can be spillable. Enabled by default when using object storage or when 'target-file-size' is greater than 'write-buffer-size'.
spill.max-disk-size
类型: 字节规格容量
必须: 否
默认值: 无
说明:
The max disk to use for write buffer spill. This only work when the write buffer spill is enabled
target-file-size
类型: 字节规格容量
必须: 否
默认值: 无
说明:
Target size of a file.
- primary key table: the default value is 128 MB.
- append table: the default value is 256 MB.
target-file-size(默认值: 128mb):- 作用: 这是 Paimon 最终期望生成的稳定数据文件(通常是经过 Compaction 合并到更高层级的文件)的目标大小。
- 原理: 在 Compaction 过程中(无论是 Universal 还是 Size-Tiered),Paimon 会尝试将输入的小文件合并,并输出大小接近
target-file-size的文件到更高的层级(如 L1, L2)。 - 影响 L0 的间接方式: 虽然
target-file-size主要影响 Compaction 的输出,但它间接影响 L0 文件的“合并潜力”。如果target-file-size设置得很大(比如 1GB),那么 Compaction 需要积累更多的 L0 小文件(累计大小达到 ~1GB)才会触发合并操作。这相当于放宽了触发 Compaction 的“累计大小”阈值。 - 注意:
target-file-size不直接控制单个 L0 文件的大小。L0 文件大小主要由write-buffer-size和 Checkpointing 决定。 - 效果: 主要在 Universal Compaction 中影响较大。因为 Universal 在合并时会尽量将一组文件合并成一个接近
target-file-size的大文件。增大target-file-size意味着 Compaction 需要积累更多的 L0 文件(总数据量更大)才会触发合并。对于 Size-Tiered,它定义了更高层级文件的大小目标,也间接影响合并策略。 - 注意: 过大的
target-file-size可能影响查询效率(读取大文件可能慢)和 Compaction 本身的资源消耗(合并更大量数据)。
default
file.format
类型: 单选
必须: 是
默认值: parquet
说明:
Specify the message format of data files, currently orc, parquet and avro are supported.
tableBucket
类型: 单行文本
必须: 是
默认值: Dynamic
说明:
bucket参数定义了表数据的存储分桶策略,这是 Paimon 的核心设计之一。不同值对应完全不同的存储和写入模式:🪣 三种 Bucket 模式详解
模式 值 特点 适用场景 固定桶模式(Fixed) >0 固定数量的桶,桶数不可变 数据分布均匀的静态表 动态桶模式(Dynamic) -1 桶数量自动扩展/收缩,根据数据量调整 数据量变化大的通用场景(推荐) 延迟桶模式(Postpone) -2 写入时不立即分桶,先存临时文件,Compaction 时才分桶 超高吞吐写入的 Append-Only 表 可选项说明: 可选
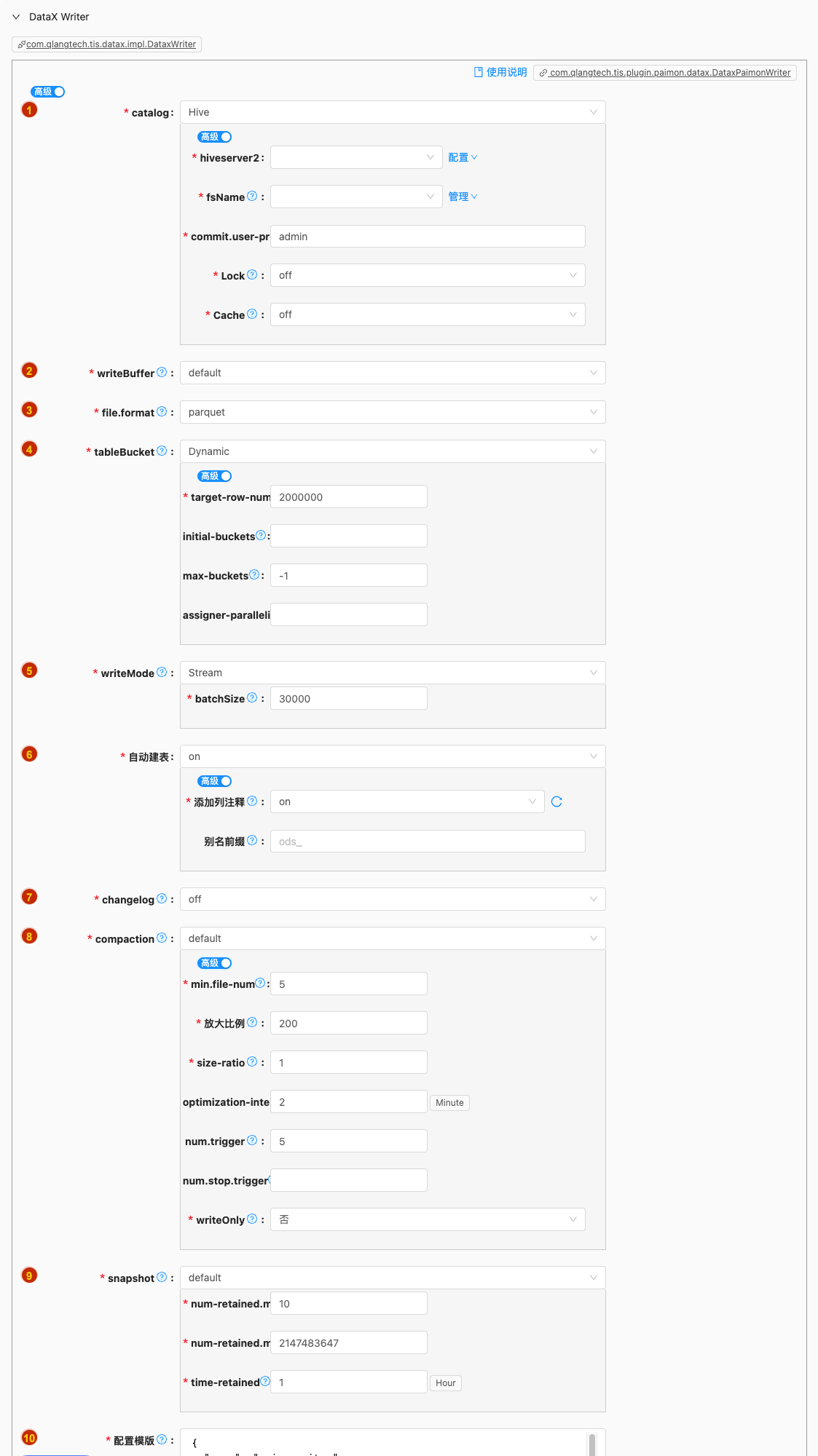
Dynamic,Fixed,Postpone以下是详细说明:Dynamic
- 配置项说明:
target-row-num
类型: 整型数字
必须: 是
默认值: 2000000
说明:
If the bucket is -1, for primary key table, is dynamic bucket mode, this option controls the target row number for one bucket.
initial-buckets
类型: 整型数字
必须: 否
默认值: 无
说明:
Initial buckets for a partition in assigner operator for dynamic bucket mode.
max-buckets
类型: 整型数字
必须: 否
默认值: -1
说明:
Max buckets for a partition in dynamic bucket mode, It should either be equal to -1 (unlimited), or it must be greater than 0 (fixed upper bound).
assigner-parallelism
类型: 整型数字
必须: 否
默认值: 无
说明:
Parallelism of assigner operator for dynamic bucket mode, it is related to the number of initialized bucket, too small will lead to insufficient processing speed of assigner.
Fixed

- 配置项说明:
bucket
类型: 整型数字
必须: 是
默认值: 无
说明:
Bucket number for file store.
It should either be equal to -1 (dynamic bucket mode), -2 (postpone bucket mode), or it must be greater than 0 (fixed bucket mode).
Postpone
writeMode
类型: 单行文本
必须: 是
默认值: Stream
说明:
Paimon 的写入模式(
write-mode)是影响数据写入行为的关键配置,batch和stream两种模式在底层实现、数据可见性和适用场景上有本质区别:🔄 核心区别对比
特性 Batch 模式 Stream 模式 设计目标 高吞吐批量处理 低延迟实时处理 数据可见性 批次完成后可见 实时可见 提交机制 显式提交(如 Flink Checkpoint) 自动增量提交 文件生成 大文件(MB-GB级) 小文件(KB-MB级) 写入延迟 秒级~分钟级 毫秒级~秒级 典型数据源 Hive/离线数仓 Kafka/CDC 流 压缩效率 高(大文件易压缩) 低(需额外小文件合并) 元数据开销 低(单个提交点) 高(频繁生成提交点) Exactly-Once 保证 依赖批处理框架 原生支持 🚀 适用场景
✅ Batch 模式最佳场景
- 离线数仓同步
- 每日全量同步 Hive 表:
write-mode=batch
- 每日全量同步 Hive 表:
- 大规模历史数据回填
- 初始化 TB 级历史数据
- 资源敏感型环境
- 机械硬盘集群(减少 IOPS 压力)
- OLAP 分析优化
✅ Stream 模式最佳场景
- 实时 CDC 管道
- 低延迟监控看板
- 实时订单看板(要求 5s 内可见)
- 事件驱动型应用
- 用户行为实时分析(点击流处理)
- 渐进式更新场景
- 离线数仓同步
可选项说明: 可选
Batch,Stream以下是详细说明:Batch
Stream

- 配置项说明:
batchSize
类型: 整型数字
必须: 是
默认值: 30000
说明:
在 Paimon 的 Stream 写入模式下,选择最佳的单次 Commit 记录数量需要平衡 数据延迟、写入效率和小文件问题三大因素。
⚠️ 必须规避的陷阱
过度追求低延迟
# 错误配置(导致小文件爆炸)
commit.interval = 1s
sink.buffer-size = 100后果:每秒生成数百小文件,NameNode 压力激增
盲目增大批次
# 错误配置(内存溢出风险)
sink.buffer-size = 1000000
execution.checkpointing.interval = 10min后果:Flink TM OOM,Checkpoint 超时失败
忽略数据特征
- 大对象场景(如图片/文档):
# 改用数据体积控制
sink.buffer-size = -1 # 禁用条数控制
sink.max-buffer-size = 128mb # 按体积Commit
- 大对象场景(如图片/文档):
📊 性能优化对照表
单Commit条数 延迟 吞吐 小文件风险 适用场景 <1,000 极低(1s内) 低 极高 实时监控告警 1,000~10,000 低(1~5s) 中等 高 实时报表/风控 10,000~50,000 中等(5~15s) 高 中 通用CDC同步 ✅ 50,000~200,000 较高(15~60s) 极高 低 历史数据回填 >200,000 高(>1min) 超高性能 极低 批量ETL(非实时) 终极建议:从 25,000条/Commit 开始(约5-10秒数据量),结合实时监控逐步调整。在精确控制延迟的场景,优先使用
commit.interval时间阈值;在高吞吐场景,优先用sink.buffer-size条数控制,并始终开启自动合并防御小文件问题。
自动建表
类型: 单行文本
必须: 是
默认值: on
说明: 无
可选项说明: 可选
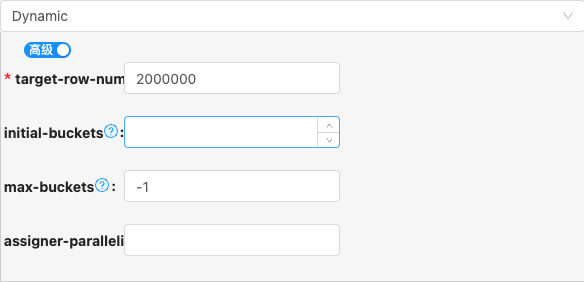
on以下是详细说明:on
- 配置项说明:
添加列注释
- 类型: 单行文本
- 必须: 是
- 默认值: on
- 说明: 在建表DDL上添加列注释,需要依赖源端表列是否定义注释,如源端列上没有列注释,则目标端建表列DDL上也没有列注释
别名前缀
- 类型: 单行文本
- 必须: 否
- 默认值: 无
- 说明: 统一为目标表添加前缀,例如在构建分层数仓用于为ods层目标表统一添加前缀,例如:
ods_erp_
changelog
类型: 单行文本
必须: 是
默认值: off
说明:
changelog-producer的作用核心功能
- 生成变更日志:将底层存储文件的物理更新(如覆盖写入)转换为逻辑变更事件(
+I/-U/+U/-D)。 - 支持流式消费:让 Flink 等引擎能像读 Kafka 一样增量读取 Paimon 表的变更(类似
SELECT * FROM table /*+ OPTIONS('scan.mode'='incremental') */)。
- 生成变更日志:将底层存储文件的物理更新(如覆盖写入)转换为逻辑变更事件(
为何需要它?
- 湖仓痛点:传统湖存储(如 Parquet)只存最终状态,缺少 "行级变更记录",无法支持增量计算。
- 流读需求:Flink CDC 等场景需要实时捕获
INSERT/UPDATE/DELETE事件。
可选项说明: 可选
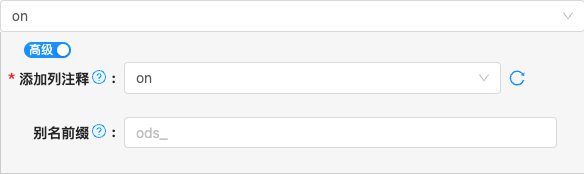
off,on以下是详细说明:off
on
- 配置项说明:
producer
类型: 单选
必须: 是
默认值: none
说明:
Whether to double write to a changelog file. This changelog file keeps the details of data changes, it can be read directly during stream reads. This can be applied to tables with primary keys.
row-deduplicate
类型: 单选
必须: 是
默认值: false
说明:
Whether to generate -U, +U changelog for the same record. This configuration is only valid for the changelog-producer is lookup or full-compaction.
deduplicate-ignore-fields
类型: 单选
必须: 是
默认值: none
说明:
Fields that are ignored for comparison while generating -U, +U changelog for the same record. This configuration is only valid for the changelog-producer.row-deduplicate is true.
compaction
类型: 单行文本
必须: 是
默认值: default
说明:
Apache Paimon 的 Compaction(压缩)机制是其核心功能之一,尤其在基于 LSM-Tree(Log-Structured Merge-Tree)架构的表格式中至关重要。它主要负责解决由频繁数据写入(尤其是流式写入)带来的小文件问题、读放大问题,并优化数据组织以提升查询性能。
Apache Paimon 的 Compaction 机制是其保证高性能、低延迟查询,尤其是处理高频更新/删除和流式写入场景的基石。它通过智能地合并小文件、清理过期数据、按主键排序数据,有效解决了 LSM-Tree 架构带来的挑战。Universal Compaction 策略因其对流式写入的友好性和易用性,成为 Paimon 的默认和推荐选项。理解并合理配置 Compaction 策略和参数,对于在生产环境中高效稳定地使用 Paimon 至关重要。
可选项说明: 可选
default以下是详细说明:default
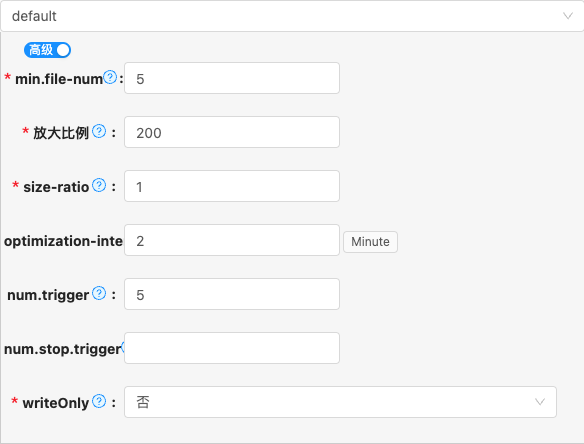
- 配置项说明:
min.file-num
类型: 整型数字
必须: 是
默认值: 5
说明:
For file set [f_0,...,f_N], the minimum file number to trigger a compaction for append-only table.
放大比例
类型: 整型数字
必须: 是
默认值: 200
说明:
The size amplification is defined as the amount (in percentage) of additional storage needed to store a single byte of data in the merge tree for changelog mode table.
size-ratio
类型: 整型数字
必须: 是
默认值: 1
说明:
Percentage flexibility while comparing sorted run size for changelog mode table. If the candidate sorted run(s) size is 1% smaller than the next sorted run's size, then include next sorted run into this candidate set.
optimization-interval
类型: 时间跨度
必须: 否
默认值: 2
说明:
Implying how often to perform an optimization compaction, this configuration is used to ensure the query timeliness of the read-optimized system table.
compaction.optimization-interval 的核心是平衡后台优化开销和数据查询/管理效率。1 分钟是安全的默认起点。 最佳值需要通过仔细监控你的特定工作负载在特定环境下的表现(资源使用、文件状态、查询延迟、写入稳定性)来确定。优先解决已观察到的瓶颈(资源争用或小文件堆积),然后进行有针对性的调整。记住,它需要与 compaction.max.file-num 和 compaction.early.max.file-num 等参数协同工作。
num.trigger
类型: 整型数字
必须: 否
默认值: 5
说明:
The sorted run number to trigger compaction. Includes level0 files (one file one sorted run) and high-level runs (one level one sorted run).
num-sorted-run.compaction-trigger = N意味着:当 Paimon 表(LSM 结构)的磁盘文件片段(Sorted Run)积累到N个时,系统会自动启动后台合并(Compaction)任务,将这些文件合并成更少、更大的文件,以优化后续的查询性能和空间利用率。 这个参数是平衡写入吞吐量和查询性能的关键杠杆之一。
num.stop.trigger
类型: 整型数字
必须: 否
默认值: 无
说明:
The number of sorted runs that trigger the stopping of writes, the default value is 'num-sorted-run.compaction-trigger' + 3.
以下是
num-sorted-run.stop-trigger的详细解释:背景:写入与合并的速率差
- 数据持续写入会不断产生新的 Sorted Run。
- 后台的 Compaction 任务负责合并这些 Sorted Run 以减少其数量。
- 理想情况下,Compaction 的速度应该能跟上写入产生新 Sorted Run 的速度,保持 Sorted Run 数量在
compaction-trigger附近波动。 - 但是,如果写入速率远远超过 Compaction 的处理能力,Sorted Run 的数量就会持续增长。
num-sorted-run.stop-trigger的核心作用- 这个参数定义了一个更高的 Sorted Run 数量阈值。
- 当磁盘上的 Sorted Run 数量达到或超过这个
stop-trigger设定的值时,Paimon 会采取强制措施:暂停(或显著减慢)新的数据写入操作。 - 简单说:它设定了“积攒的文件片段(Sorted Run)数量达到某个危险上限时,必须停止写入,优先让合并追赶上来”。
writeOnly
类型: 单选
必须: 是
默认值: false
说明:
If set to true, compactions and snapshot expiration will be skipped. This option is used along with dedicated compact jobs.
snapshot
类型: 单行文本
必须: 是
默认值: default
说明:
Apache Paimon 的 Snapshot(快照)机制 是其实现多版本并发控制(MVCC)、时间旅行查询(Time Travel)、增量计算和数据一致性的核心基础。它借鉴了 Iceberg 等现代数据表格式的设计思想,为存储在 Paimon 表中的数据提供了原子性、一致性、隔离性和持久性(ACID)的保证,特别适用于流批一体和实时更新的场景。
可选项说明: 可选
default以下是详细说明:default
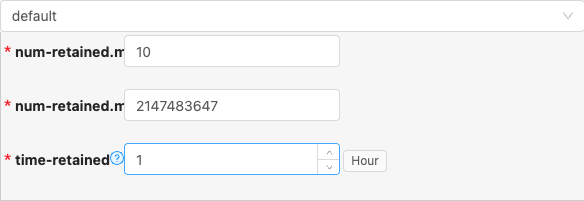
- 配置项说明:
num-retained.min
类型: 整型数字
必须: 是
默认值: 10
说明:
The minimum number of completed snapshots to retain. Should be greater than or equal to 1.
num-retained.max
类型: 整型数字
必须: 是
默认值: 2147483647
说明:
The maximum number of completed snapshots to retain. Should be greater than or equal to the minimum number.
time-retained
类型: 时间跨度
必须: 是
默认值: 1
说明:
The maximum time of completed snapshots to retain.
unit:hour
配置模版
- 类型: 富文本
- 必须: 是
- 默认值: com.qlangtech.tis.plugin.paimon.datax.DataxPaimonWriter.getDftTemplate()
- 说明: 无特殊情况请不要修改模版内容,避免不必要的错误
实时写
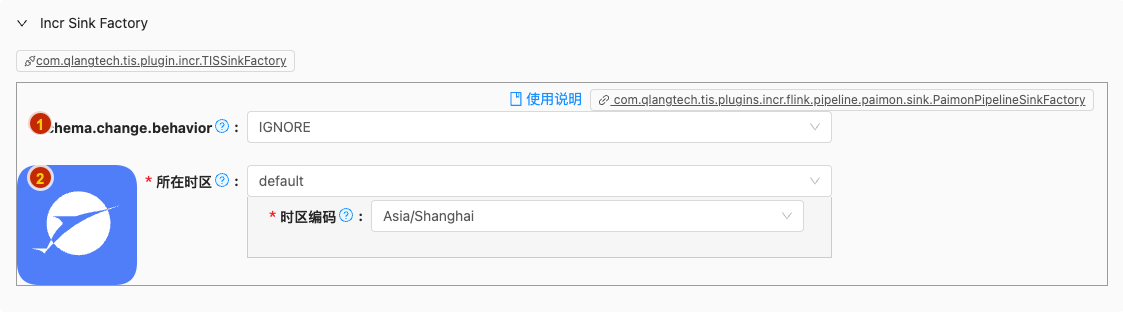
- 配置项说明:
schema.change.behavior
类型: 单选
必须: 是
默认值: IGNORE
说明:
Behavior for handling schema change events.
- IGNORE: Drop all schema change events.
- LENIENT: Apply schema changes to downstream tolerantly, and keeps executing if applying fails.
- TRY_EVOLVE: Apply schema changes to downstream, but keeps executing if applying fails.
- EVOLVE: Apply schema changes to downstream. This requires sink to support handling schema changes.
- EXCEPTION: Throw an exception to terminate the sync pipeline.
所在时区
类型: 单行文本
必须: 是
默认值: default
说明:
在 Flink CDC 同步任务中,
timeZone参数的作用是解决跨时区时间数据的一致性问题,核心要点如下:可选项说明: 可选
customize,default以下是详细说明:customize

- 配置项说明:
时区编码
- 类型: 单行文本
- 必须: 是
- 默认值: 无
- 说明: 设置服务端所在时区编码
default

- 配置项说明:
时区编码
- 类型: 单选
- 必须: 是
- 默认值: com.qlangtech.tis.plugin.timezone.TISTimeZone.dftZoneId()
- 说明: 选择服务端所在时区