SqlServer
数据源配置
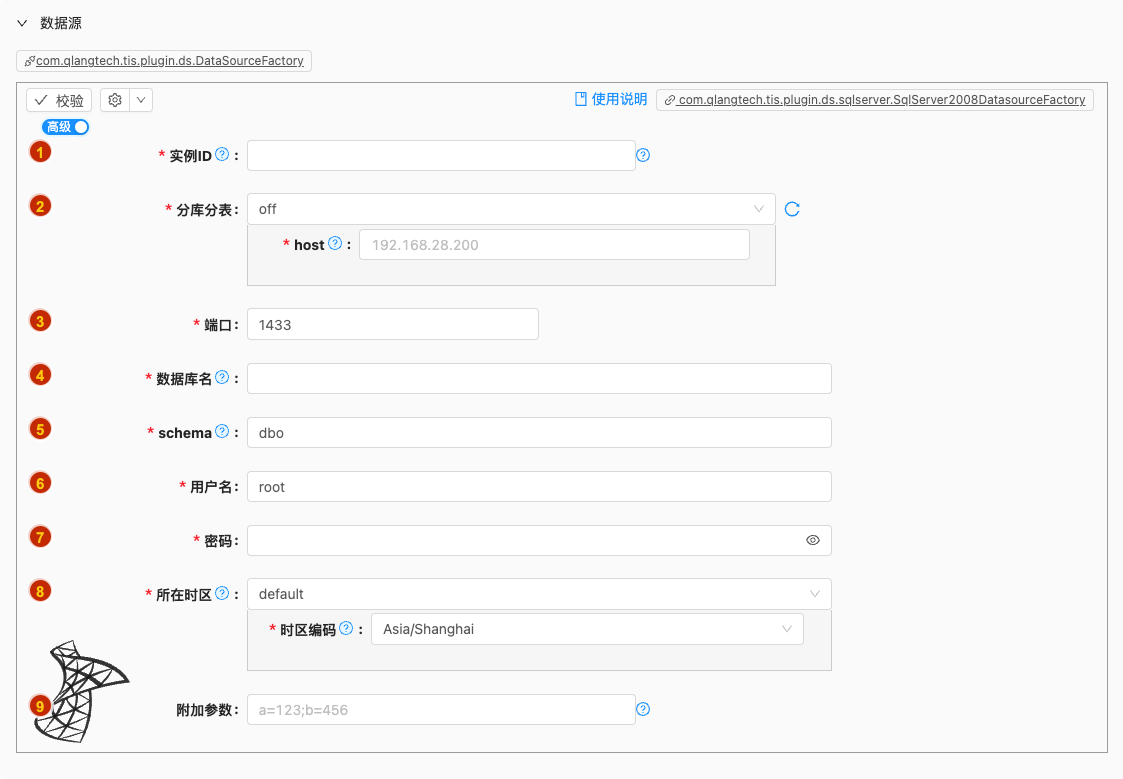
- 配置项说明:
实例ID
- 类型: 单行文本
- 必须: 是
- 默认值: 无
- 说明: 数据源实例名称,请起一个有意义且唯一的名称
分库分表
类型: 单行文本
必须: 是
默认值: off
说明: 无
可选项说明: 可选
off,on以下是详细说明:off

- 配置项说明:
host
- 类型: 单行文本
- 必须: 是
- 默认值: 无
- 说明: 服务器节点连接地址,可以为IP或者域名
on

- 配置项说明:
分库节点
类型: 富文本
必须: 是
默认值: 无
说明:
将分布在多个数据库冗余节点中的物理表视作一个逻辑表,在数据同步管道中进行配置,输入框中可输入以下内容:
192.168.28.200[00-07]: 单节点多库,导入 192.168.28.200:3306 节点的 order00,order01,order02,order03,order04,order05,order06,order078个库。也可以将节点描述写成:192.168.28.200[0-7],则会导入 192.168.28.200:3306 节点的 order0,order1,order2,order3,order4,order5,order6,order78个库192.168.28.200[00-07],192.168.28.201[08-15]:会导入 192.168.28.200:3306 节点的 order00,order01,order02,order03,order04,order05,order06,order078个库 和 192.168.28.201:3306 节点的 order08,order09,order10,order11,order12,order13,order14,order158个库,共计16个库
分表识别
类型: 单行文本
必须: 否
默认值: 无
说明:
识别分表的正则式,默认识别分表策略为
(tabname)_\d+, 如需使用其他分表策略,如带字母[a-z]的后缀则需要用户自定义注意:如输入自定义正则式,表达式中逻辑表名部分,必须要用括号括起来,不然无法从物理表名中抽取出逻辑表名。
测试表
- 类型: 单行文本
- 必须: 是
- 默认值: 无
- 说明: 提交表单用户测试,所填正则式是否能正确识别物理分表。输入需要识别的逻辑表名,点击‘校验’按钮会进行自动识别。
增量前缀匹配
类型: 单选
必须: 是
默认值: false
说明:
使用前缀匹配的样式,在flink-cdc表前缀通配匹配的场景中使用
- 选择
是:在增量监听流程中使用逻辑表+*的方式对目标表监听,例如,逻辑表名为base,启动时使用base*对数据库中base01,base02启用增量监听,在运行期用户又增加了base03表则执行逻辑会自动对base03表开启监听 - 选择
否:在增量监听流程中使用物理表全匹配的方式进行匹配。在运行期用户增加的新的分表忽略,如需对新加的分表增量监听生效,需要重启增量执行管道。
- 选择
端口
- 类型: 整型数字
- 必须: 是
- 默认值: 1433
- 说明: 无
数据库名
- 类型: 单行文本
- 必须: 是
- 默认值: 无
- 说明: 数据库名,创建JDBC实例时用
schema
- 类型: 单行文本
- 必须: 是
- 默认值: dbo
- 说明: Specify the schema (or several schema separated by commas) to be set in the search-path. This schema will be used to resolve unqualified object names used in statements over this connection.
用户名
- 类型: 单行文本
- 必须: 是
- 默认值: root
- 说明: 无
密码
- 类型: 密码
- 必须: 是
- 默认值: 无
- 说明: 无
所在时区
类型: 单行文本
必须: 是
默认值: default
说明: 设置服务端所在时区,有两种输入方式:1. default 从下拉框中选择,2. customize:用户手动输入时区编码
可选项说明: 可选
customize,default以下是详细说明:customize

- 配置项说明:
时区编码
- 类型: 单行文本
- 必须: 是
- 默认值: 无
- 说明: 设置服务端所在时区编码
default

- 配置项说明:
时区编码
- 类型: 单选
- 必须: 是
- 默认值: com.qlangtech.tis.plugin.timezone.TISTimeZone.dftZoneId()
- 说明: 选择服务端所在时区
附加参数
- 类型: 单行文本
- 必须: 否
- 默认值: 无
- 说明: 无
批量读
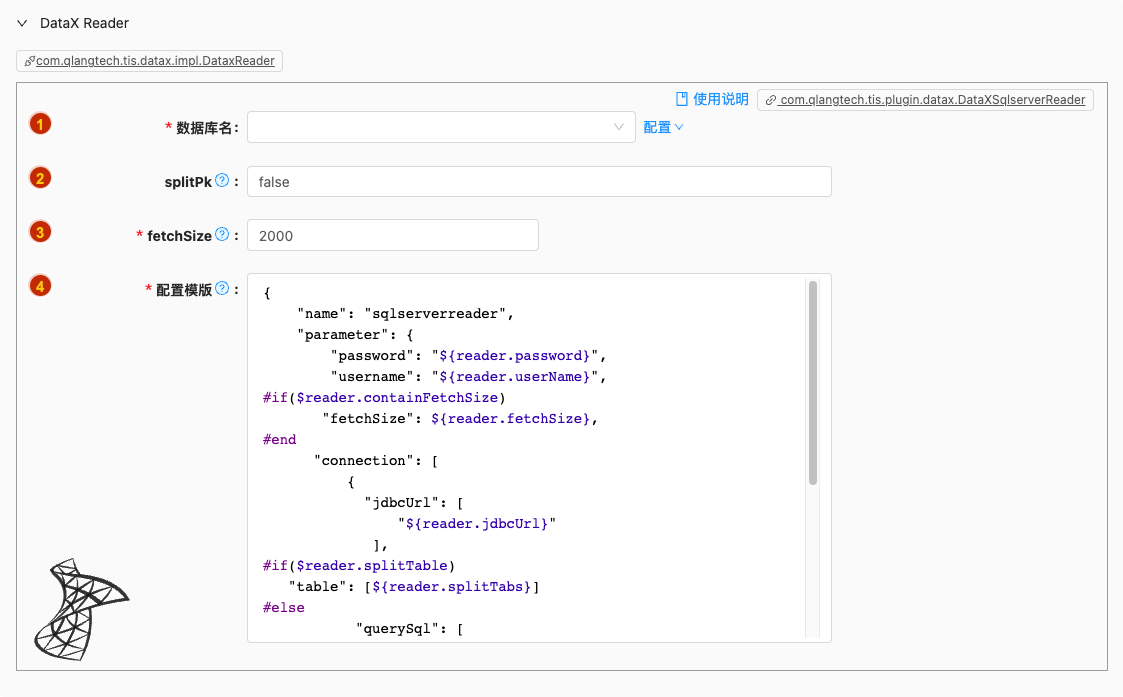
- 配置项说明:
数据库名
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 无
splitPk
- 类型: 单行文本
- 必须: 否
- 默认值: false
- 说明: SqlServerReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。 推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。 目前splitPk仅支持整形型数据切分,不支持浮点、字符串、日期等其他类型。如果用户指定其他非支持类型,SqlServerReader将报错! splitPk设置为空,底层将视作用户不允许对单表进行切分,因此使用单通道进行抽取。
fetchSize
- 类型: 整型数字
- 必须: 是
- 默认值: 2000
- 说明: 该配置项定义了插件和数据库服务器端每次批量数据获取条数,该值决定了DataX和服务器端的网络交互次数,能够较大的提升数据抽取性能。
配置模版
- 类型: 富文本
- 必须: 是
- 默认值: com.qlangtech.tis.plugin.datax.DataXSqlserverReader.getDftTemplate()
- 说明: 无特殊情况请不要修改模版内容,避免不必要的错误
批量写
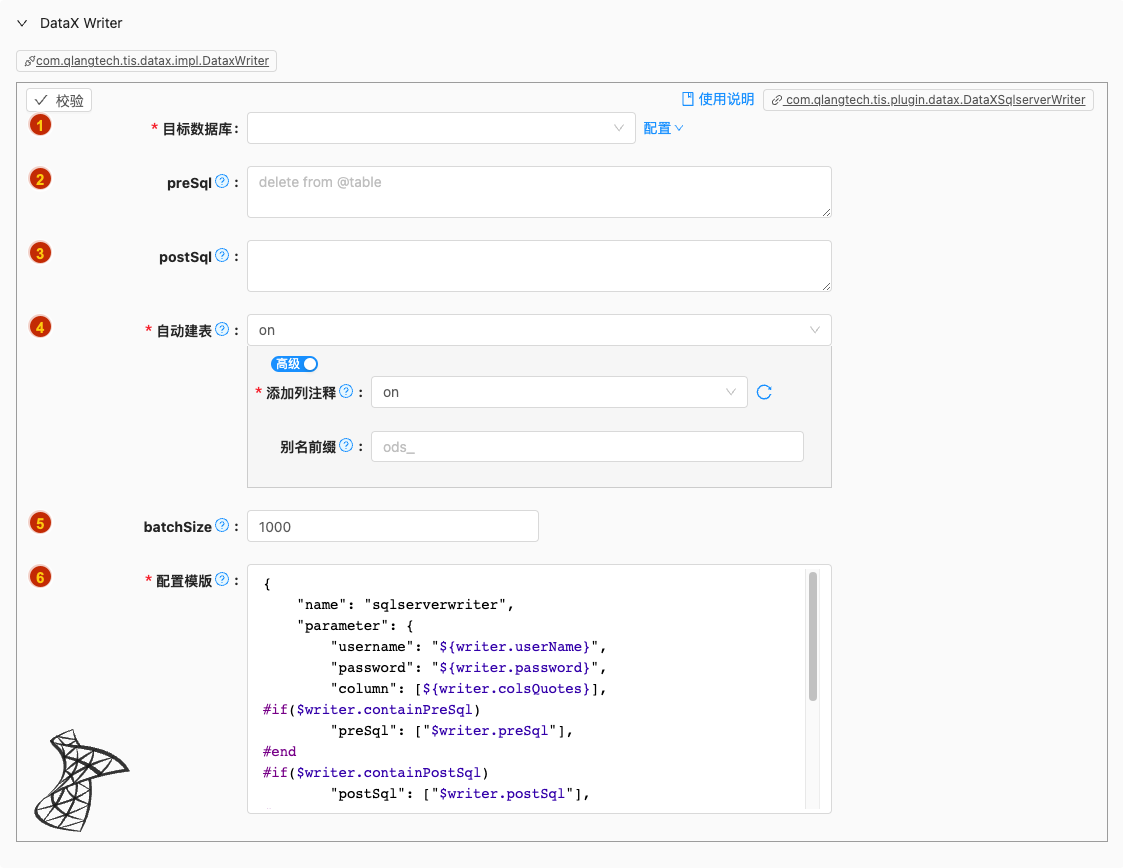
- 配置项说明:
目标数据库
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 无
preSql
类型: 富文本
必须: 否
默认值: 无
说明:
描述:写入数据到目的表前,会先执行这里的标准语句。如果 Sql 中有你需要操作到的表名称,请使用
@table表示,这样在实际执行 Sql 语句时,会对变量按照实际表名称进行替换。比如你的任务是要写入到目的端的100个同构分表(表名称为:datax_00,datax01, ... datax_98,datax_99),并且你希望导入数据前,先对表中数据进行删除操作,那么你可以这样配置:"preSql":["delete from 表名"],效果是:在执行到每个表写入数据前,会先执行对应的 delete from 对应表名称
postSql
类型: 富文本
必须: 否
默认值: 无
说明:
写入数据到目的表后,会执行这里的标准语句。(原理同 preSql )
自动建表
类型: 单行文本
必须: 是
默认值: on
说明:
解析Reader的元数据,自动生成Writer create table DDL语句,有三种选择:
off:关闭自动生成及同步目标端建表DDL语句,当目标端表实例已经存在可选择此选项。default:打开动生成及自动执行目标端建表DDL语句,执行任务状态由程序自动控制毋需人为干涉。customized:用户可自定义设置自动执行目标端建表DDL语句逻辑,如:是否需要生成列注释等。
可选项说明: 可选
off,on以下是详细说明:off

- 配置项说明:
别名前缀
- 类型: 单行文本
- 必须: 否
- 默认值: 无
- 说明: 统一为目标表添加前缀,例如在构建分层数仓用于为ods层目标表统一添加前缀,例如:
ods_erp_
on
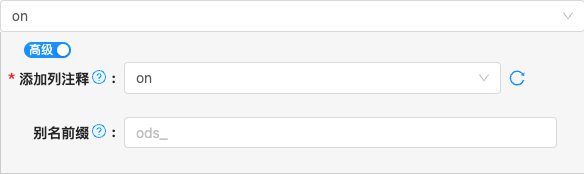
- 配置项说明:
添加列注释
- 类型: 单行文本
- 必须: 是
- 默认值: on
- 说明: 在建表DDL上添加列注释,需要依赖源端表列是否定义注释,如源端列上没有列注释,则目标端建表列DDL上也没有列注释
别名前缀
- 类型: 单行文本
- 必须: 否
- 默认值: 无
- 说明: 统一为目标表添加前缀,例如在构建分层数仓用于为ods层目标表统一添加前缀,例如:
ods_erp_
batchSize
类型: 整型数字
必须: 否
默认值: 1000
说明:
- 描述:一次性批量提交的记录数大小,该值可以极大减少DataX与Mysql的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进程OOM情况。
配置模版
- 类型: 富文本
- 必须: 是
- 默认值: com.qlangtech.tis.plugin.datax.DataXSqlserverWriter.getDftTemplate()
- 说明: 无特殊情况请不要修改模版内容,避免不必要的错误
实时读
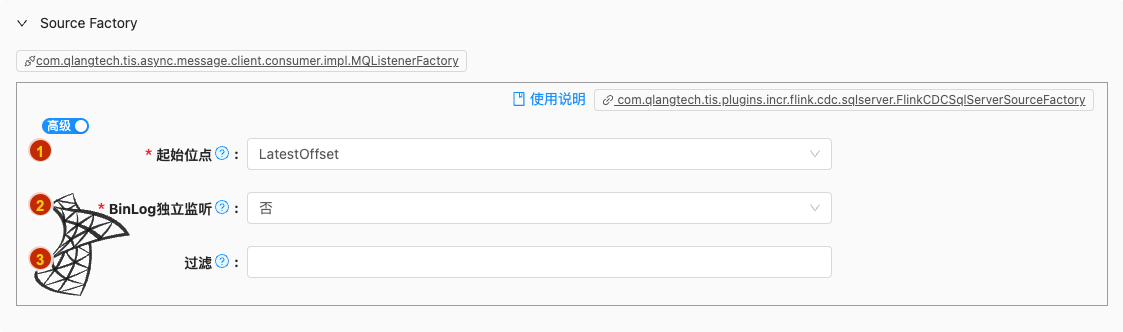
- 配置项说明:
起始位点
类型: 单行文本
必须: 是
默认值: LatestOffset
说明:
Initial: Takes a snapshot of structure and data of captured tables; useful if topics should be populated with a complete representation of the data from the captured tables.Snapshot: Takes a snapshot of structure and data like initial but instead does not transition into streaming changes once the snapshot has completed.LatestOffset(default): Takes a snapshot of the structure of captured tables only; useful if only changes happening from now onwards should be propagated to topics.
可选项说明: 可选
Initial,LatestOffset,Snapshot以下是详细说明:Initial
LatestOffset
Snapshot
BinLog独立监听
类型: 单选
必须: 是
默认值: false
说明:
执行Flink任务过程中,Binlog监听分配独立的Slot计算资源不会与下游计算算子混合在一起。
如开启,带来的好处是运算时资源各自独立不会相互相互影响,弊端是,上游算子与下游算子独立在两个Solt中需要额外的网络传输开销
过滤
- 类型: 单选
- 必须: 否
- 默认值: 无
- 说明: 可以将数据流中将某一种事件类型的事件过滤掉,有以下几种类型可以选择:INSERT, UPDATE_BEFORE, UPDATE_AFTER, DELETE
实时写
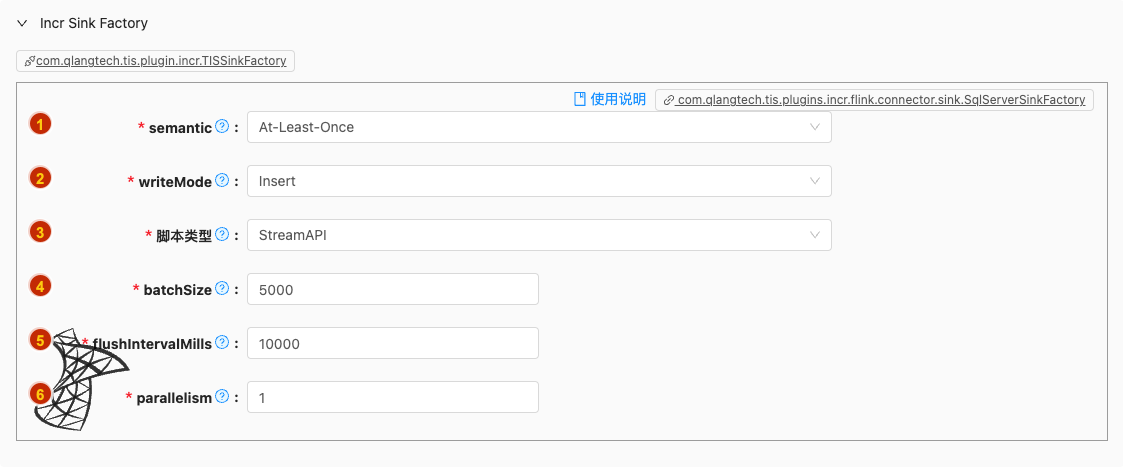
- 配置项说明:
semantic
类型: 单选
必须: 是
默认值: at-least-once
说明:
描述: sink 端是否支持二阶段提交
注意: 如果此参数为空,默认不开启二阶段提交,即 sink 端不支持 exactly_once 语义; 当前只支持 exactly-once 和 at-least-once
writeMode
类型: 单选
必须: 是
默认值: insert
说明:
控制写入数据到目标表采用
insert into或者replace into或者ON DUPLICATE KEY UPDATE语句
脚本类型
类型: 单行文本
必须: 是
默认值: StreamAPI
说明:
TIS 为您自动生成 Flink Stream 脚本,现支持两种类型脚本:
SQL: 优点逻辑清晰,便于用户自行修改执行逻辑Stream API:优点基于系统更底层执行逻辑执行、轻量、高性能
可选项说明: 可选
SQL,StreamAPI以下是详细说明:SQL
StreamAPI
batchSize
类型: 整型数字
必须: 是
默认值: 5000
说明:
描述:一次性批量提交的记录数大小,该值可以极大减少 ChunJun 与数据库的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成 ChunJun 运行进程 OOM 情况
flushIntervalMills
- 类型: 整型数字
- 必须: 是
- 默认值: 10000
- 说明: "the flush interval mills, over this time, asynchronous threads will flush data. The default value is 10s.
parallelism
- 类型: 整型数字
- 必须: 是
- 默认值: 1
- 说明: sink 并行度